Proximal Policy Gradient (PPO)
Overview
PPO is one of the most popular DRL algorithms. It runs reasonably fast by leveraging vector (parallel) environments and naturally works well with different action spaces, therefore supporting a variety of games. It also has good sample efficiency compared to algorithms such as DQN.
Original paper:
Reference resources:
- Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
- What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
- ⭐ The 37 Implementation Details of Proximal Policy Optimization
All our PPO implementations below are augmented with the same code-level optimizations presented in openai/baselines's PPO. To achieve this, see how we matched the implementation details in our blog post The 37 Implementation Details of Proximal Policy Optimization.
Implemented Variants
| Variants Implemented | Description |
|---|---|
ppo.py, docs |
For classic control tasks like CartPole-v1. |
ppo_atari.py, docs |
For Atari games. It uses convolutional layers and common atari-based pre-processing techniques. |
ppo_continuous_action.py, docs |
For continuous action space. Also implemented Mujoco-specific code-level optimizations. |
ppo_atari_lstm.py, docs |
For Atari games using LSTM without stacked frames. |
ppo_atari_envpool.py, docs |
Uses the blazing fast Envpool Atari vectorized environment. |
ppo_atari_envpool_xla_jax.py, docs |
Uses the blazing fast Envpool Atari vectorized environment with EnvPool's XLA interface and JAX. |
ppo_procgen.py, docs |
For the procgen environments. |
ppo_atari_multigpu.py, docs |
For Atari environments leveraging multi-GPUs. |
ppo_pettingzoo_ma_atari.py, docs |
For Pettingzoo's multi-agent Atari environments. |
Below are our single-file implementations of PPO:
ppo.py
The ppo.py has the following features:
- Works with the
Boxobservation space of low-level features - Works with the
Discreteaction space - Works with envs like
CartPole-v1
Usage
poetry install
python cleanrl/ppo.py --help
python cleanrl/ppo.py --env-id CartPole-v1
Explanation of the logged metrics
Running python cleanrl/ppo.py will automatically record various metrics such as actor or value losses in Tensorboard. Below is the documentation for these metrics:
charts/episodic_return: episodic return of the gamecharts/episodic_length: episodic length of the gamecharts/SPS: number of steps per secondcharts/learning_rate: the current learning ratelosses/value_loss: the mean value loss across all data pointslosses/policy_loss: the mean policy loss across all data pointslosses/entropy: the mean entropy value across all data pointslosses/old_approx_kl: the approximate Kullback–Leibler divergence, measured by(-logratio).mean(), which corresponds to the k1 estimator in John Schulman’s blog post on approximating KLlosses/approx_kl: better alternative toolad_approx_klmeasured by(logratio.exp() - 1) - logratio, which corresponds to the k3 estimator in approximating KLlosses/clipfrac: the fraction of the training data that triggered the clipped objectivelosses/explained_variance: the explained variance for the value function
Implementation details
ppo.py is based on the "13 core implementation details" in The 37 Implementation Details of Proximal Policy Optimization, which are as follows:
- Vectorized architecture ( common/cmd_util.py#L22)
- Orthogonal Initialization of Weights and Constant Initialization of biases ( a2c/utils.py#L58))
- The Adam Optimizer's Epsilon Parameter ( ppo2/model.py#L100)
- Adam Learning Rate Annealing ( ppo2/ppo2.py#L133-L135)
- Generalized Advantage Estimation ( ppo2/runner.py#L56-L65)
- Mini-batch Updates ( ppo2/ppo2.py#L157-L166)
- Normalization of Advantages ( ppo2/model.py#L139)
- Clipped surrogate objective ( ppo2/model.py#L81-L86)
- Value Function Loss Clipping ( ppo2/model.py#L68-L75)
- Overall Loss and Entropy Bonus ( ppo2/model.py#L91)
- Global Gradient Clipping ( ppo2/model.py#L102-L108)
- Debug variables ( ppo2/model.py#L115-L116)
- Separate MLP networks for policy and value functions ( common/policies.py#L156-L160, baselines/common/models.py#L75-L103)
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo.py. To ensure the quality of the implementation, we compared the results against openai/baselies' PPO.
| Environment | ppo.py |
openai/baselies' PPO (Huang et al., 2022)1 |
|---|---|---|
| CartPole-v1 | 492.40 ± 13.05 | 497.54 ± 4.02 |
| Acrobot-v1 | -89.93 ± 6.34 | -81.82 ± 5.58 |
| MountainCar-v0 | -200.00 ± 0.00 | -200.00 ± 0.00 |
Learning curves:
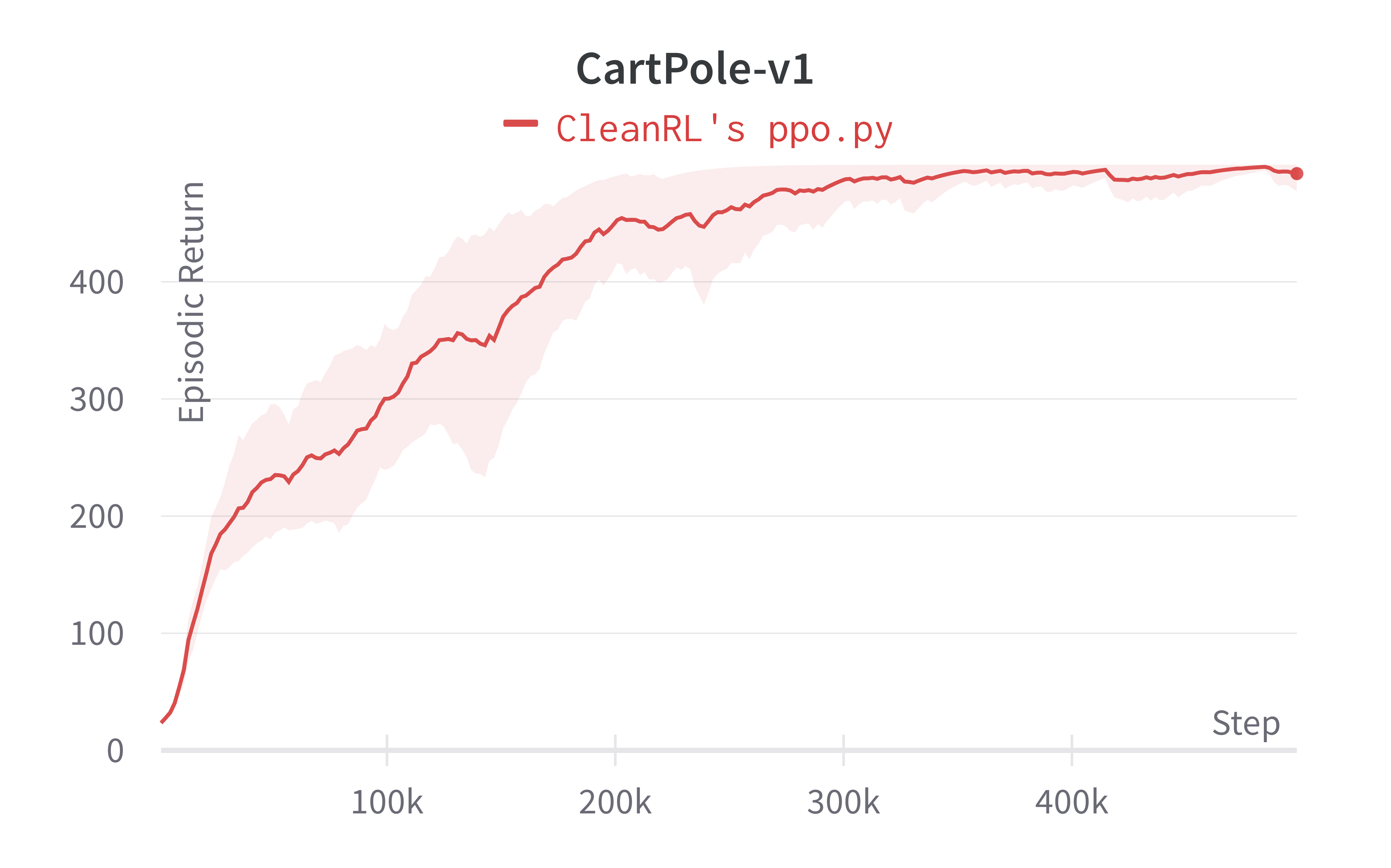
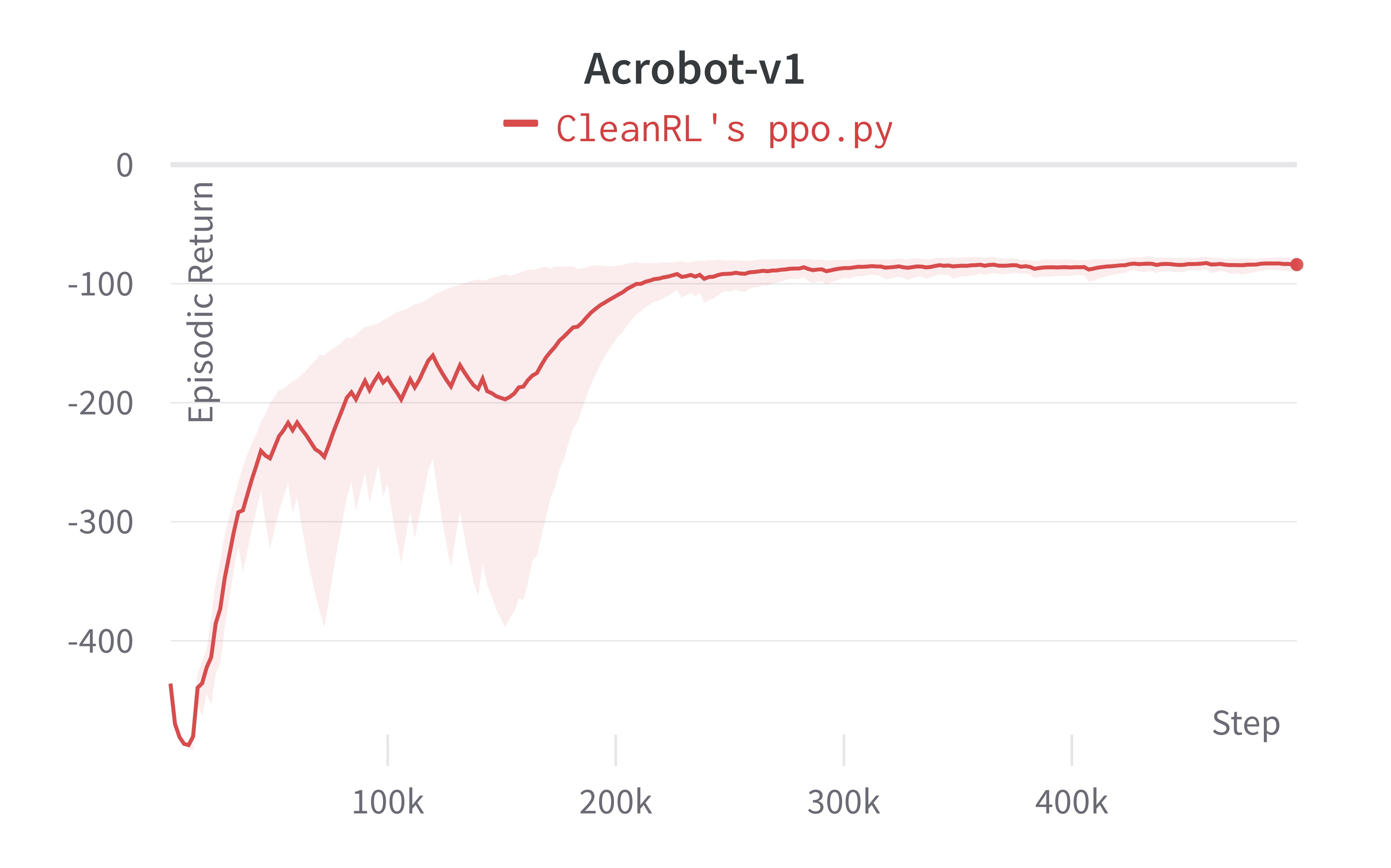
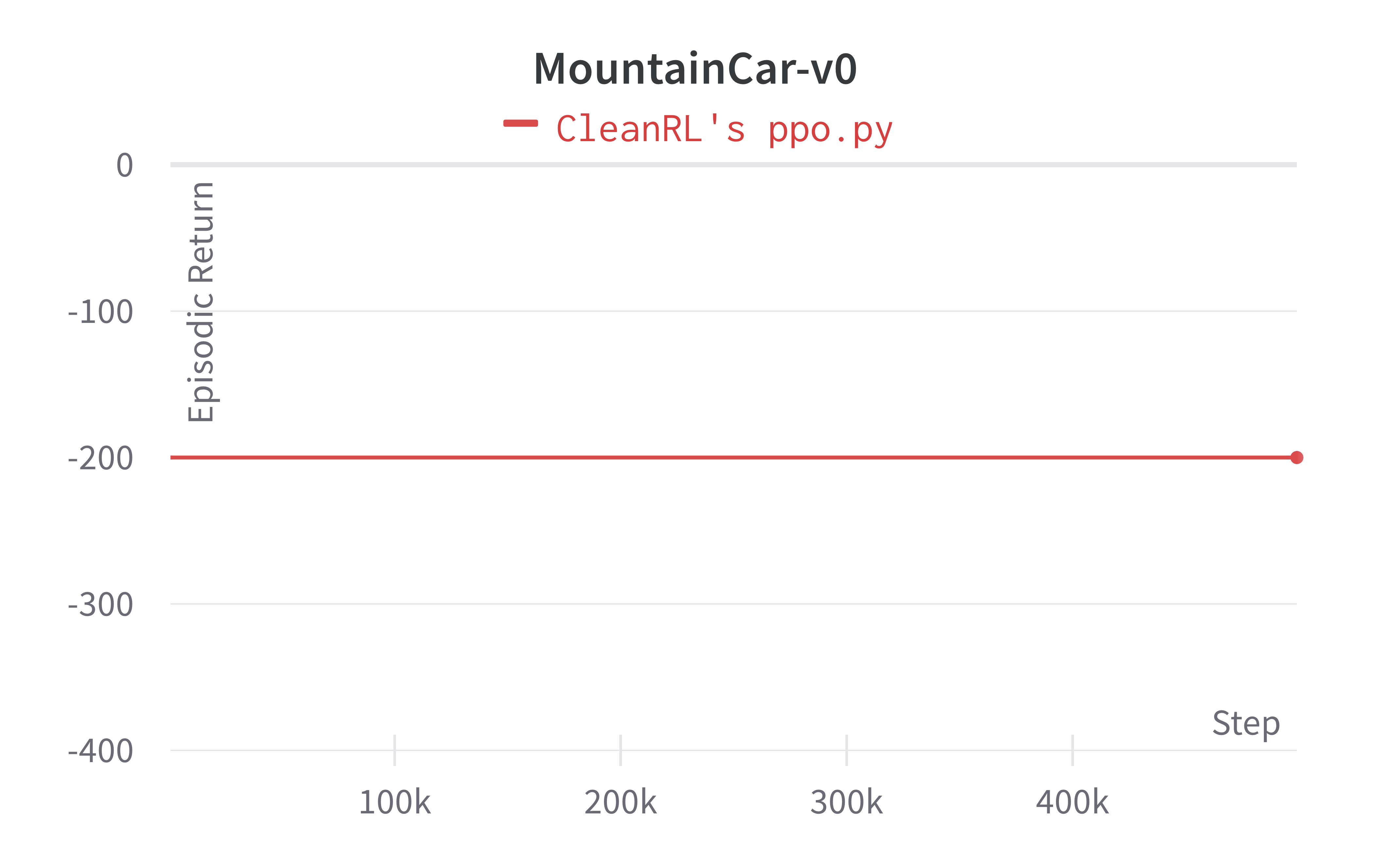
Tracked experiments and game play videos:
Video tutorial
If you'd like to learn ppo.py in-depth, consider checking out the following video tutorial:
ppo_atari.py
The ppo_atari.py has the following features:
- For Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Usage
poetry install --with atari
python cleanrl/ppo_atari.py --help
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_atari.py is based on the "9 Atari implementation details" in The 37 Implementation Details of Proximal Policy Optimization, which are as follows:
- The Use of
NoopResetEnv( common/atari_wrappers.py#L12) - The Use of
MaxAndSkipEnv( common/atari_wrappers.py#L97) - The Use of
EpisodicLifeEnv( common/atari_wrappers.py#L61) - The Use of
FireResetEnv( common/atari_wrappers.py#L41) - The Use of
WarpFrame(Image transformation) common/atari_wrappers.py#L134 - The Use of
ClipRewardEnv( common/atari_wrappers.py#L125) - The Use of
FrameStack( common/atari_wrappers.py#L188) - Shared Nature-CNN network for the policy and value functions ( common/policies.py#L157, common/models.py#L15-L26)
- Scaling the Images to Range [0, 1] ( common/models.py#L19)
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo_atari.py. To ensure the quality of the implementation, we compared the results against openai/baselies' PPO.
| Environment | ppo_atari.py |
openai/baselies' PPO (Huang et al., 2022)1 |
|---|---|---|
| BreakoutNoFrameskip-v4 | 416.31 ± 43.92 | 406.57 ± 31.554 |
| PongNoFrameskip-v4 | 20.59 ± 0.35 | 20.512 ± 0.50 |
| BeamRiderNoFrameskip-v4 | 2445.38 ± 528.91 | 2642.97 ± 670.37 |
Learning curves:
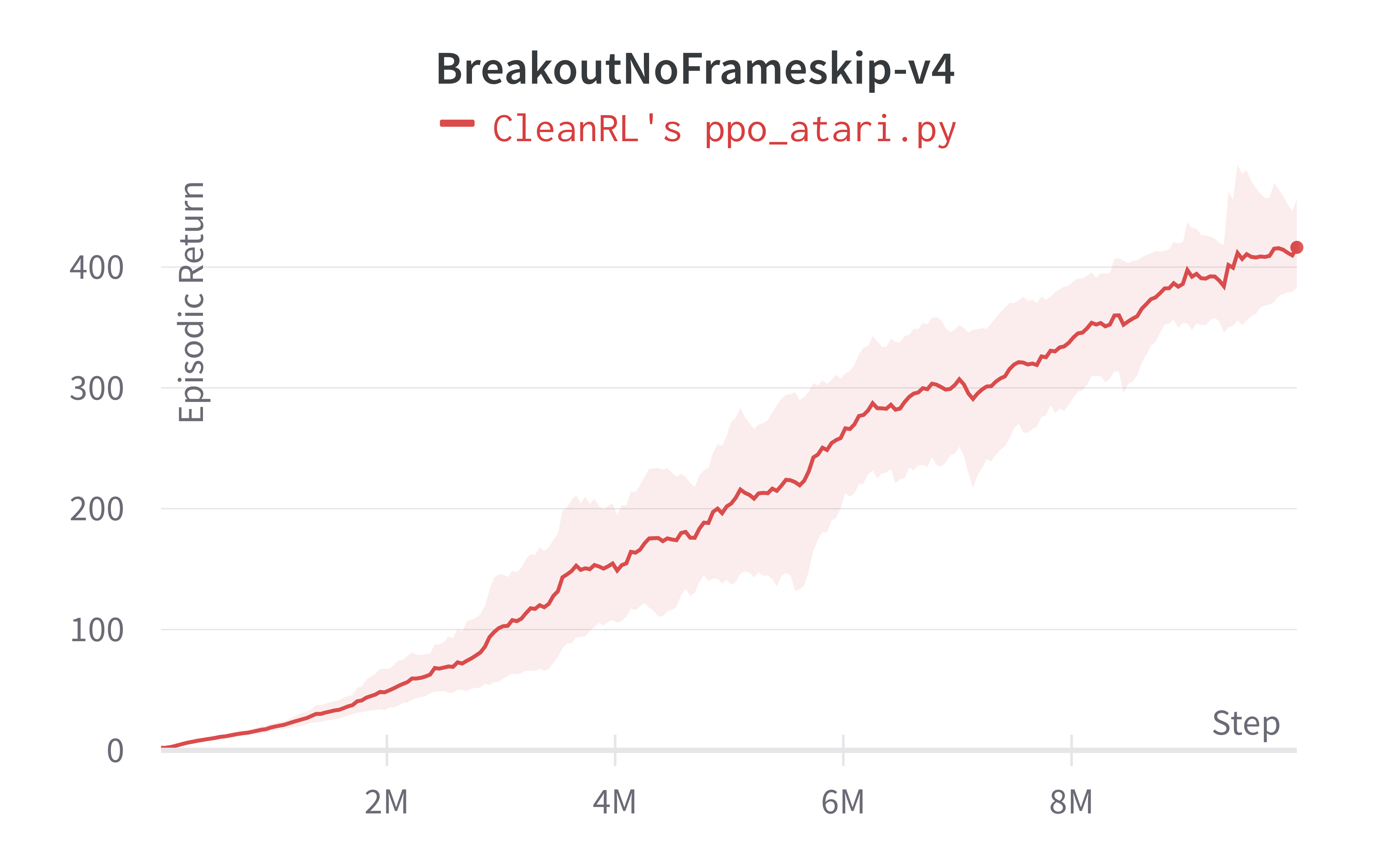
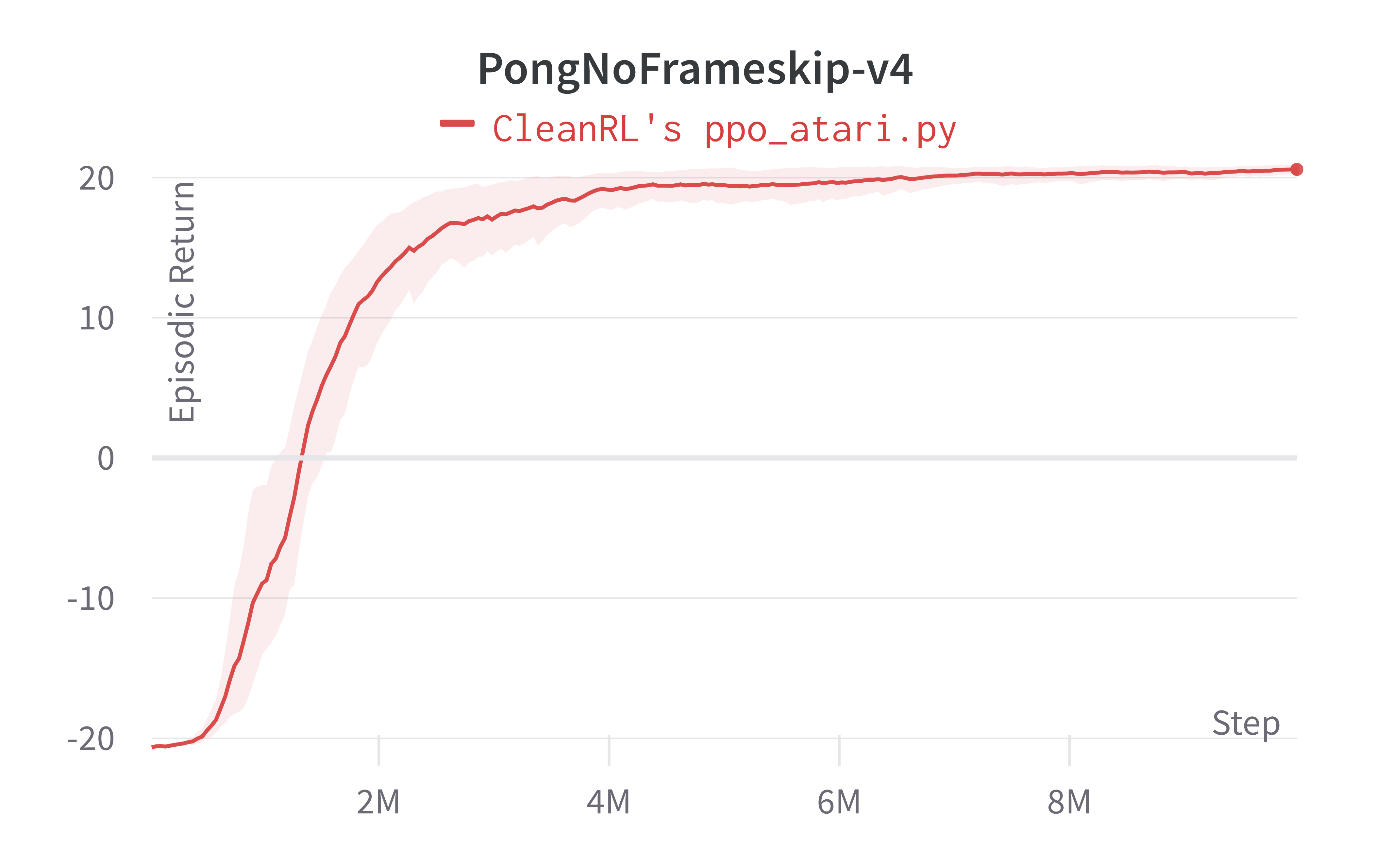
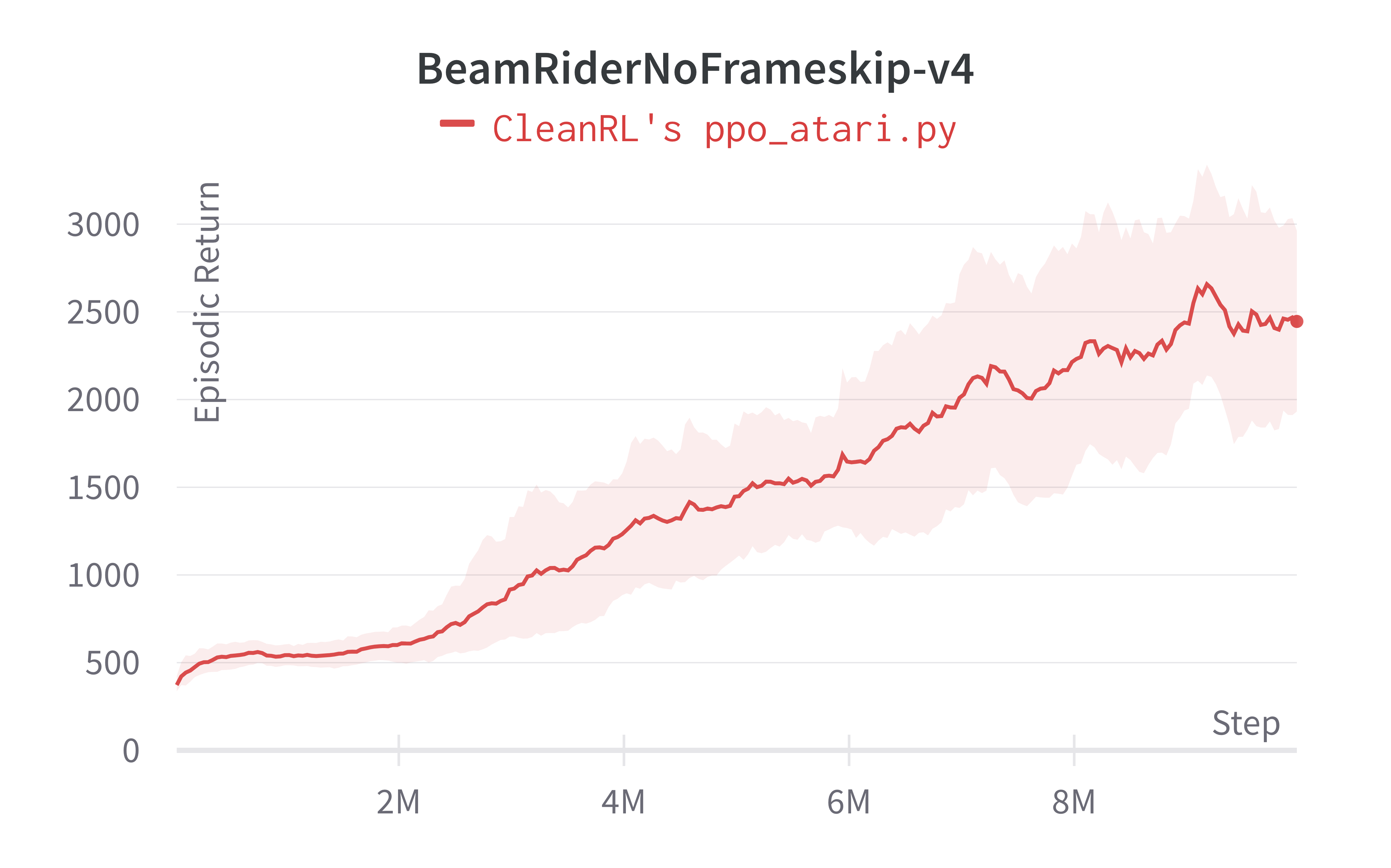
Tracked experiments and game play videos:
Video tutorial
If you'd like to learn ppo_atari.py in-depth, consider checking out the following video tutorial:
ppo_continuous_action.py
The ppo_continuous_action.py has the following features:
- For continuous action space. Also implemented Mujoco-specific code-level optimizations
- Works with the
Boxobservation space of low-level features - Works with the
Box(continuous) action space - adding experimental support for Gymnasium
- 🧪 support
dm_controlenvironments via Shimmy
Usage
# mujoco v4 environments
poetry install --with mujoco
python cleanrl/ppo_continuous_action.py --help
python cleanrl/ppo_continuous_action.py --env-id Hopper-v2
# dm_control v4 environments
poetry install --with mujoco,dm_control
python cleanrl/ppo_continuous_action.py --env-id dm_control/cartpole-balance-v0
# backwards compatibility with mujoco v2 environments
poetry install --with mujoco_py,mujoco
python cleanrl/ppo_continuous_action.py --env-id Hopper-v2
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_continuous_action.py is based on the "9 details for continuous action domains (e.g. Mujoco)" in The 37 Implementation Details of Proximal Policy Optimization, which are as follows:
- Continuous actions via normal distributions ( common/distributions.py#L103-L104)
- State-independent log standard deviation ( common/distributions.py#L104)
- Independent action components ( common/distributions.py#L238-L246)
- Separate MLP networks for policy and value functions ( common/policies.py#L160, baselines/common/models.py#L75-L103
- Handling of action clipping to valid range and storage ( common/cmd_util.py#L99-L100)
- Normalization of Observation ( common/vec_env/vec_normalize.py#L4)
- Observation Clipping ( common/vec_env/vec_normalize.py#L39)
- Reward Scaling ( common/vec_env/vec_normalize.py#L28)
- Reward Clipping ( common/vec_env/vec_normalize.py#L32)
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Result tables, learning curves, and interactive reports
Below are the average episodic returns for ppo_continuous_action.py. To ensure the quality of the implementation, we compared the results against openai/baselies' PPO.
| ppo_continuous_action ({'tag': ['v1.0.0-27-gde3f410']}) | openai/baselies' PPO (results taken from here) |
|
|---|---|---|
| HalfCheetah-v2 | 2262.50 ± 1196.81 | 1428.55 ± 62.40 |
| Walker2d-v2 | 3312.32 ± 429.87 | 3356.49 ± 322.61 |
| Hopper-v2 | 2311.49 ± 440.99 | 2158.65 ± 302.33 |
| InvertedPendulum-v2 | 852.04 ± 17.04 | 901.25 ± 35.73 |
| Humanoid-v2 | 676.34 ± 78.68 | 673.11 ± 53.02 |
| Pusher-v2 | -60.49 ± 4.37 | -56.83 ± 13.33 |
Learning curves:
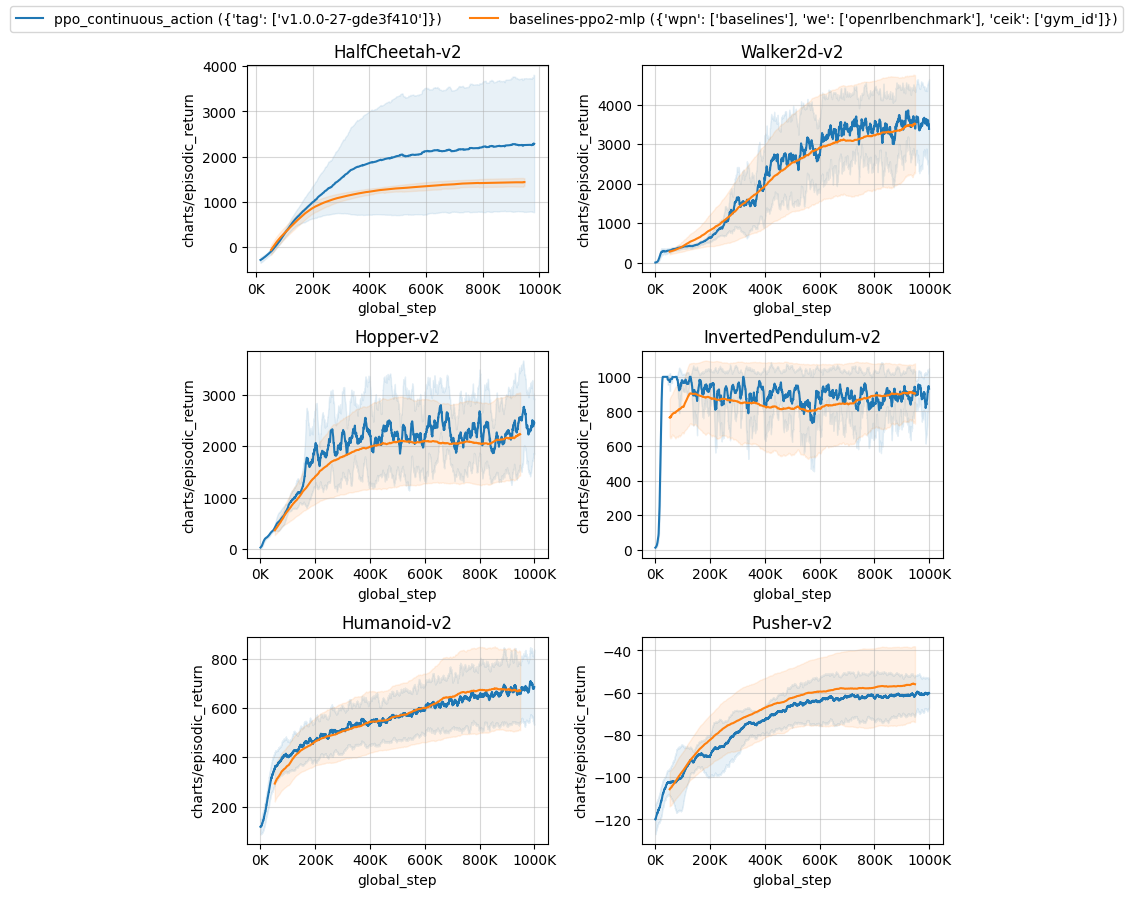
Tracked experiments and game play videos:
Below are the average episodic returns for ppo_continuous_action.py in MuJoCo v4 environments and dm_control environments.
| ppo_continuous_action ({'tag': ['v1.0.0-12-g99f7789']}) | |
|---|---|
| HalfCheetah-v4 | 2905.85 ± 1129.37 |
| Walker2d-v4 | 2890.97 ± 231.40 |
| Hopper-v4 | 2051.80 ± 313.94 |
| InvertedPendulum-v4 | 950.98 ± 36.39 |
| Humanoid-v4 | 742.19 ± 155.77 |
| Pusher-v4 | -55.60 ± 3.98 |
Learning curves:
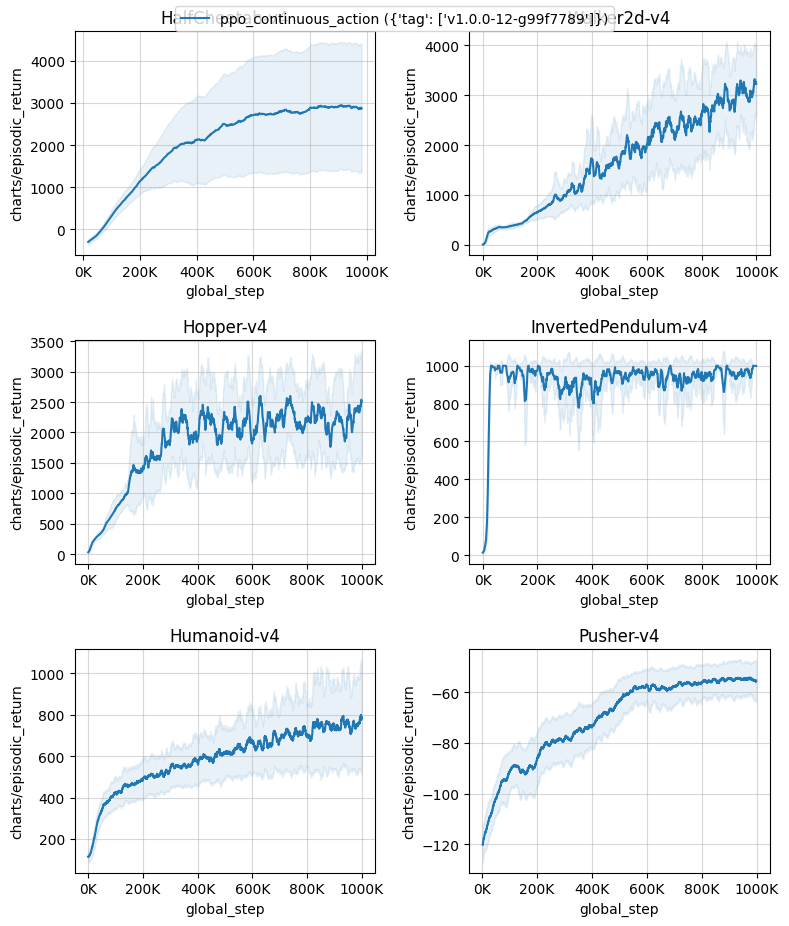
Tracked experiments and game play videos:
Below are the average episodic returns for ppo_continuous_action.py in dm_control environments.
| ppo_continuous_action ({'tag': ['v1.0.0-13-gcbd83f6']}) | |
|---|---|
| dm_control/acrobot-swingup-v0 | 27.84 ± 9.25 |
| dm_control/acrobot-swingup_sparse-v0 | 1.60 ± 1.17 |
| dm_control/ball_in_cup-catch-v0 | 900.78 ± 5.26 |
| dm_control/cartpole-balance-v0 | 855.47 ± 22.06 |
| dm_control/cartpole-balance_sparse-v0 | 999.93 ± 0.10 |
| dm_control/cartpole-swingup-v0 | 640.86 ± 11.44 |
| dm_control/cartpole-swingup_sparse-v0 | 51.34 ± 58.35 |
| dm_control/cartpole-two_poles-v0 | 203.86 ± 11.84 |
| dm_control/cartpole-three_poles-v0 | 164.59 ± 3.23 |
| dm_control/cheetah-run-v0 | 432.56 ± 82.54 |
| dm_control/dog-stand-v0 | 307.79 ± 46.26 |
| dm_control/dog-walk-v0 | 120.05 ± 8.80 |
| dm_control/dog-trot-v0 | 76.56 ± 6.44 |
| dm_control/dog-run-v0 | 60.25 ± 1.33 |
| dm_control/dog-fetch-v0 | 34.26 ± 2.24 |
| dm_control/finger-spin-v0 | 590.49 ± 171.09 |
| dm_control/finger-turn_easy-v0 | 180.42 ± 44.91 |
| dm_control/finger-turn_hard-v0 | 61.40 ± 9.59 |
| dm_control/fish-upright-v0 | 516.21 ± 59.52 |
| dm_control/fish-swim-v0 | 87.91 ± 6.83 |
| dm_control/hopper-stand-v0 | 2.72 ± 1.72 |
| dm_control/hopper-hop-v0 | 0.52 ± 0.48 |
| dm_control/humanoid-stand-v0 | 6.59 ± 0.18 |
| dm_control/humanoid-walk-v0 | 1.73 ± 0.03 |
| dm_control/humanoid-run-v0 | 1.11 ± 0.04 |
| dm_control/humanoid-run_pure_state-v0 | 0.98 ± 0.03 |
| dm_control/humanoid_CMU-stand-v0 | 4.79 ± 0.18 |
| dm_control/humanoid_CMU-run-v0 | 0.88 ± 0.05 |
| dm_control/manipulator-bring_ball-v0 | 0.50 ± 0.29 |
| dm_control/manipulator-bring_peg-v0 | 1.80 ± 1.58 |
| dm_control/manipulator-insert_ball-v0 | 35.50 ± 13.04 |
| dm_control/manipulator-insert_peg-v0 | 60.40 ± 21.76 |
| dm_control/pendulum-swingup-v0 | 242.81 ± 245.95 |
| dm_control/point_mass-easy-v0 | 273.95 ± 362.28 |
| dm_control/point_mass-hard-v0 | 143.25 ± 38.12 |
| dm_control/quadruped-walk-v0 | 239.03 ± 66.17 |
| dm_control/quadruped-run-v0 | 180.44 ± 32.91 |
| dm_control/quadruped-escape-v0 | 28.92 ± 11.21 |
| dm_control/quadruped-fetch-v0 | 193.97 ± 22.20 |
| dm_control/reacher-easy-v0 | 626.28 ± 15.51 |
| dm_control/reacher-hard-v0 | 443.80 ± 9.64 |
| dm_control/stacker-stack_2-v0 | 75.68 ± 4.83 |
| dm_control/stacker-stack_4-v0 | 68.02 ± 4.02 |
| dm_control/swimmer-swimmer6-v0 | 158.19 ± 10.22 |
| dm_control/swimmer-swimmer15-v0 | 131.94 ± 0.88 |
| dm_control/walker-stand-v0 | 564.46 ± 235.22 |
| dm_control/walker-walk-v0 | 392.51 ± 56.25 |
| dm_control/walker-run-v0 | 125.92 ± 10.01 |
Note that the dm_control/lqr-lqr_2_1-v0 dm_control/lqr-lqr_6_2-v0 environments are never terminated or truncated. See https://wandb.ai/openrlbenchmark/cleanrl/runs/3tm00923 and https://wandb.ai/openrlbenchmark/cleanrl/runs/1z9us07j as an example.
Learning curves:
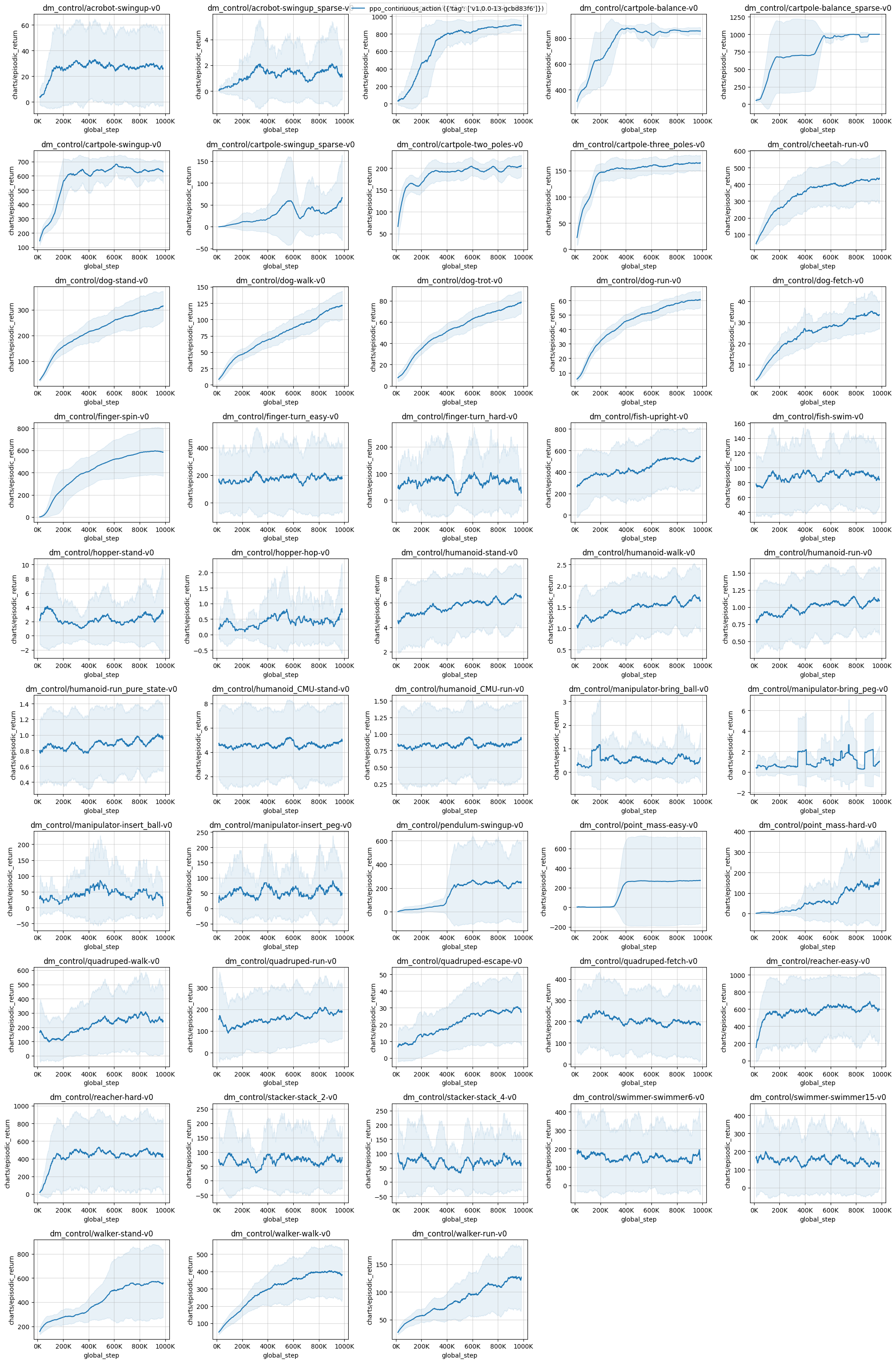
Tracked experiments and game play videos:
Info
In the gymnasium environments, we use the v4 mujoco environments, which roughly results in the same performance as the v2 mujoco environments.
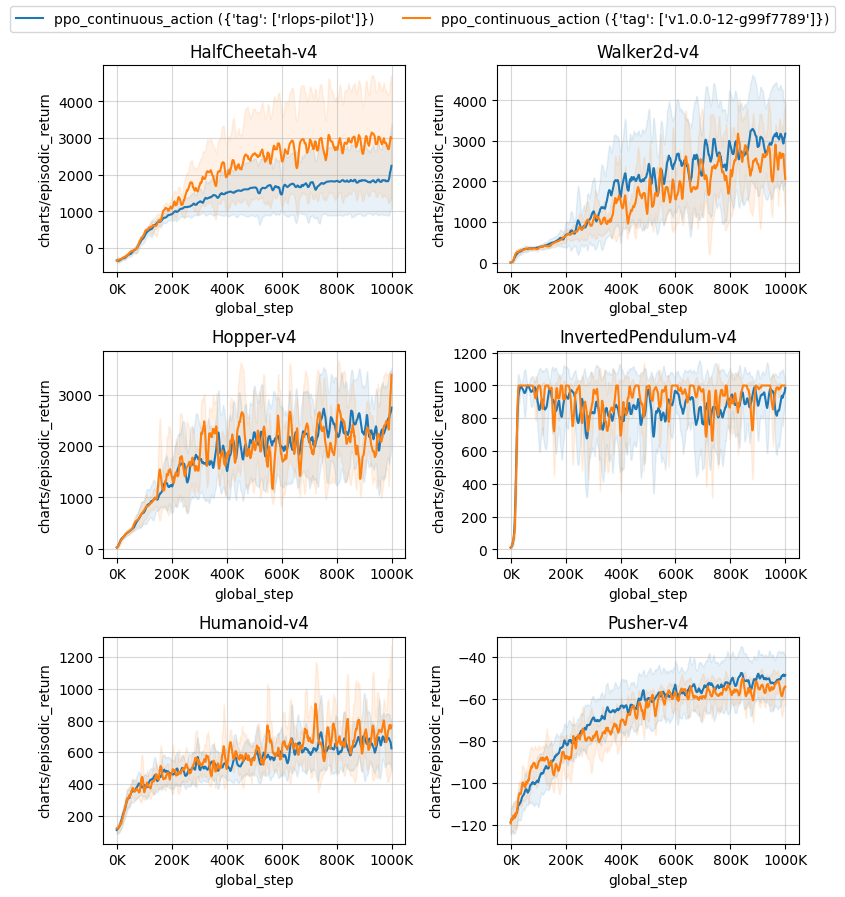
Video tutorial
If you'd like to learn ppo_continuous_action.py in-depth, consider checking out the following video tutorial:
ppo_atari_lstm.py
The ppo_atari_lstm.py has the following features:
- For Atari games using LSTM without stacked frames. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Usage
poetry install --with atari
python cleanrl/ppo_atari_lstm.py --help
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_atari_lstm.py is based on the "5 LSTM implementation details" in The 37 Implementation Details of Proximal Policy Optimization, which are as follows:
- Layer initialization for LSTM layers ( a2c/utils.py#L84-L86)
- Initialize the LSTM states to be zeros ( common/models.py#L179)
- Reset LSTM states at the end of the episode ( common/models.py#L141)
- Prepare sequential rollouts in mini-batches ( a2c/utils.py#L81)
- Reconstruct LSTM states during training ( a2c/utils.py#L81)
To help test out the memory, we remove the 4 stacked frames from the observation (i.e., using env = gym.wrappers.FrameStack(env, 1) instead of env = gym.wrappers.FrameStack(env, 4) like in ppo_atari.py )
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo_atari_lstm.py. To ensure the quality of the implementation, we compared the results against openai/baselies' PPO.
| Environment | ppo_atari_lstm.py |
openai/baselies' PPO (Huang et al., 2022)1 |
|---|---|---|
| BreakoutNoFrameskip-v4 | 128.92 ± 31.10 | 138.98 ± 50.76 |
| PongNoFrameskip-v4 | 19.78 ± 1.58 | 19.79 ± 0.67 |
| BeamRiderNoFrameskip-v4 | 1536.20 ± 612.21 | 1591.68 ± 372.95 |
Learning curves:
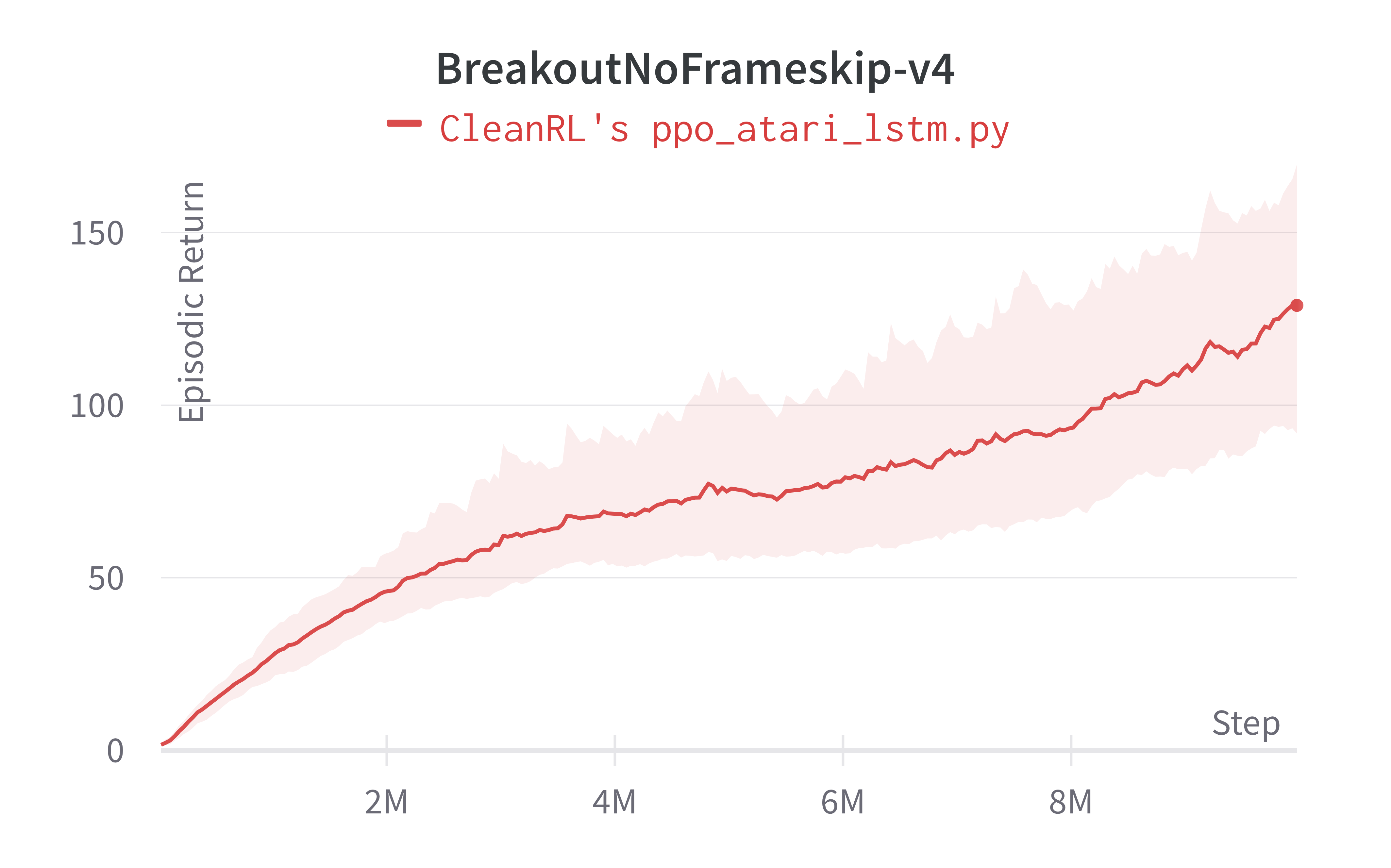
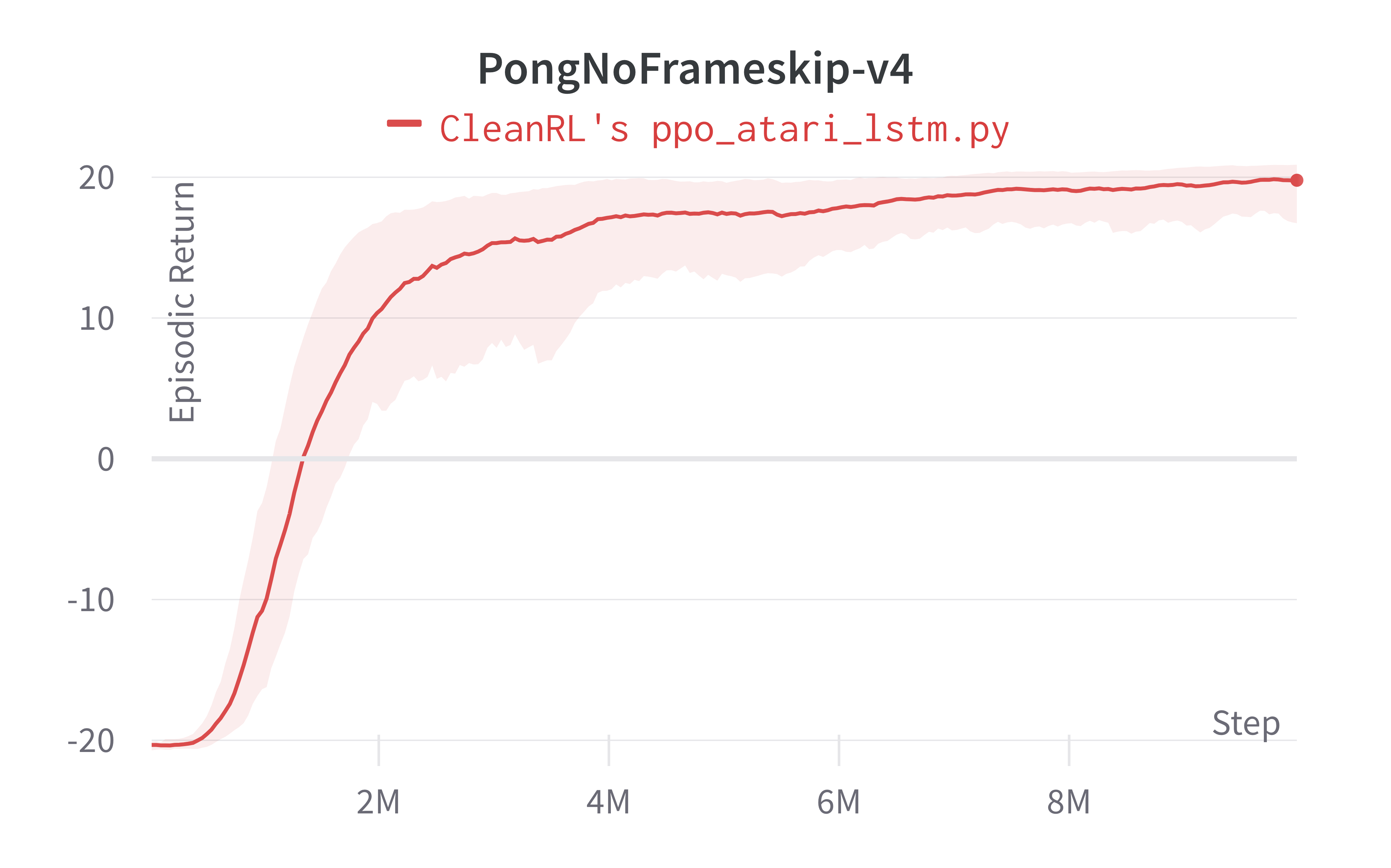
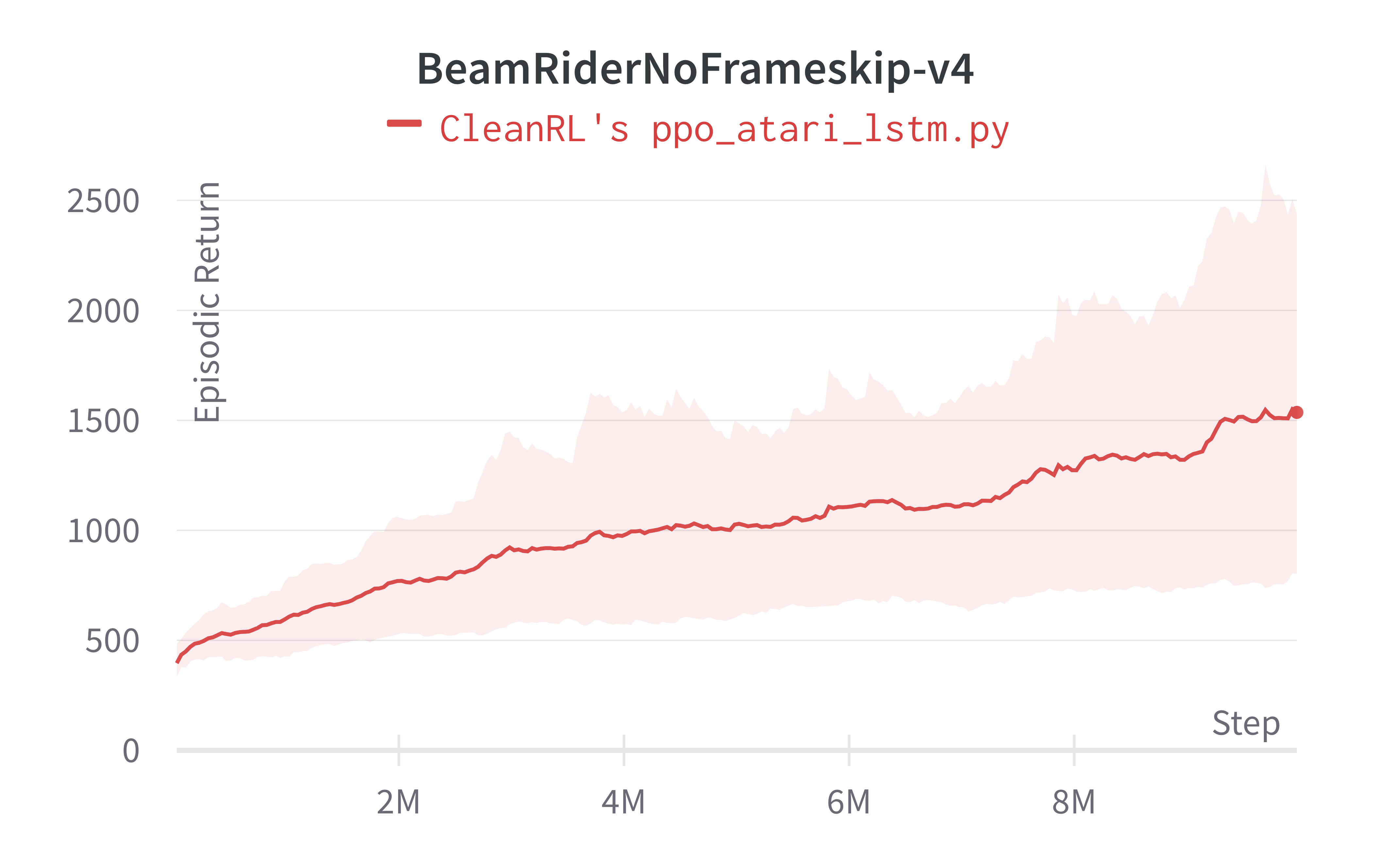
Tracked experiments and game play videos:
ppo_atari_envpool.py
The ppo_atari_envpool.py has the following features:
- Uses the blazing fast Envpool vectorized environment.
- For Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Warning
Note that ppo_atari_envpool.py does not work in Windows and MacOs . See envpool's built wheels here: https://pypi.org/project/envpool/#files
Bug
EnvPool's vectorized environment does not behave the same as gym's vectorized environment, which causes a compatibility bug in our PPO implementation. When an action \(a\) results in an episode termination or truncation, the environment generates \(s_{last}\) as the terminated or truncated state; we then use \(s_{new}\) to denote the initial state of the new episodes. Here is how the bahviors differ:
- Under the vectorized environment of
envpool<=0.6.4, theobsinobs, reward, done, info = env.step(action)is the truncated state \(s_{last}\) - Under the vectorized environment of
gym==0.23.1, theobsinobs, reward, done, info = env.step(action)is the initial state \(s_{new}\).
This causes the \(s_{last}\) to be off by one. See sail-sg/envpool#194 for more detail. However, it does not seem to impact performance, so we take a note here and await for the upstream fix.
Usage
poetry install --with envpool
python cleanrl/ppo_atari_envpool.py --help
python cleanrl/ppo_atari_envpool.py --env-id Breakout-v5
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_atari_envpool.py uses a customized RecordEpisodeStatistics to work with envpool but has the same other implementation details as ppo_atari.py (see related docs).
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo_atari_envpool.py. Notice it has the same sample efficiency as ppo_atari.py, but runs about 3x faster.
| Environment | ppo_atari_envpool.py (~80 mins) |
ppo_atari.py (~220 mins) |
|---|---|---|
| BreakoutNoFrameskip-v4 | 389.57 ± 29.62 | 416.31 ± 43.92 |
| PongNoFrameskip-v4 | 20.55 ± 0.37 | 20.59 ± 0.35 |
| BeamRiderNoFrameskip-v4 | 2039.83 ± 1146.62 | 2445.38 ± 528.91 |
Learning curves:
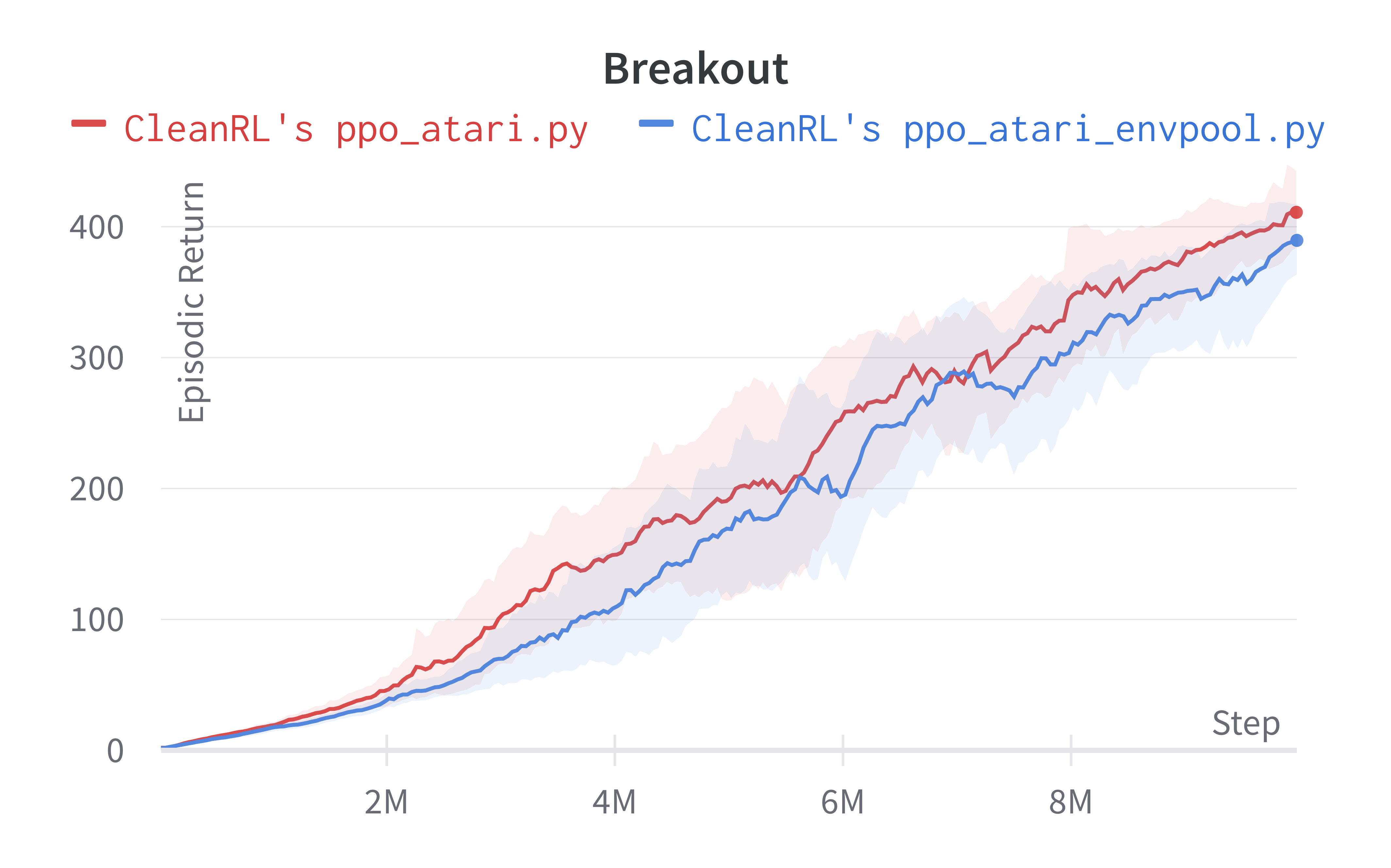
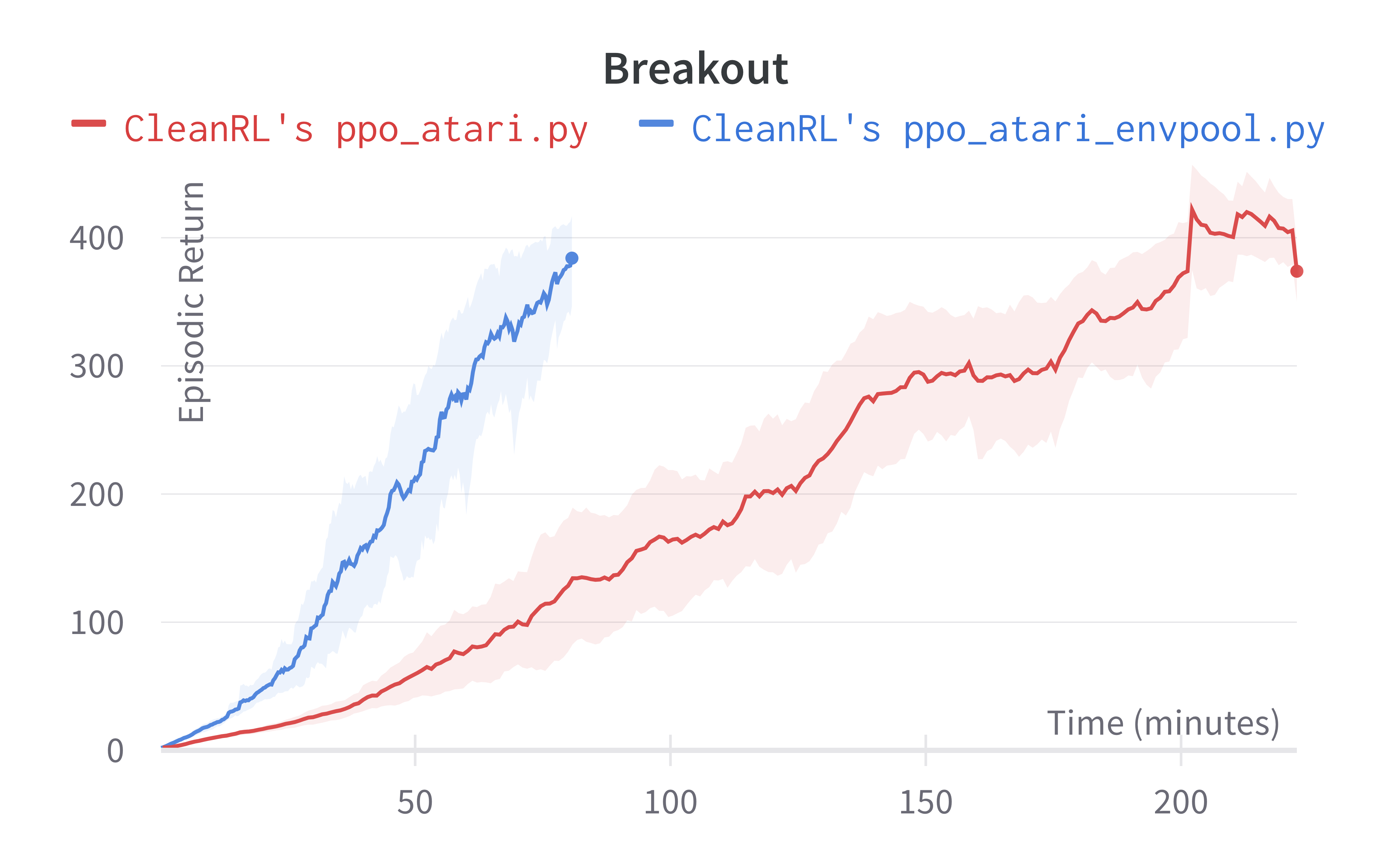
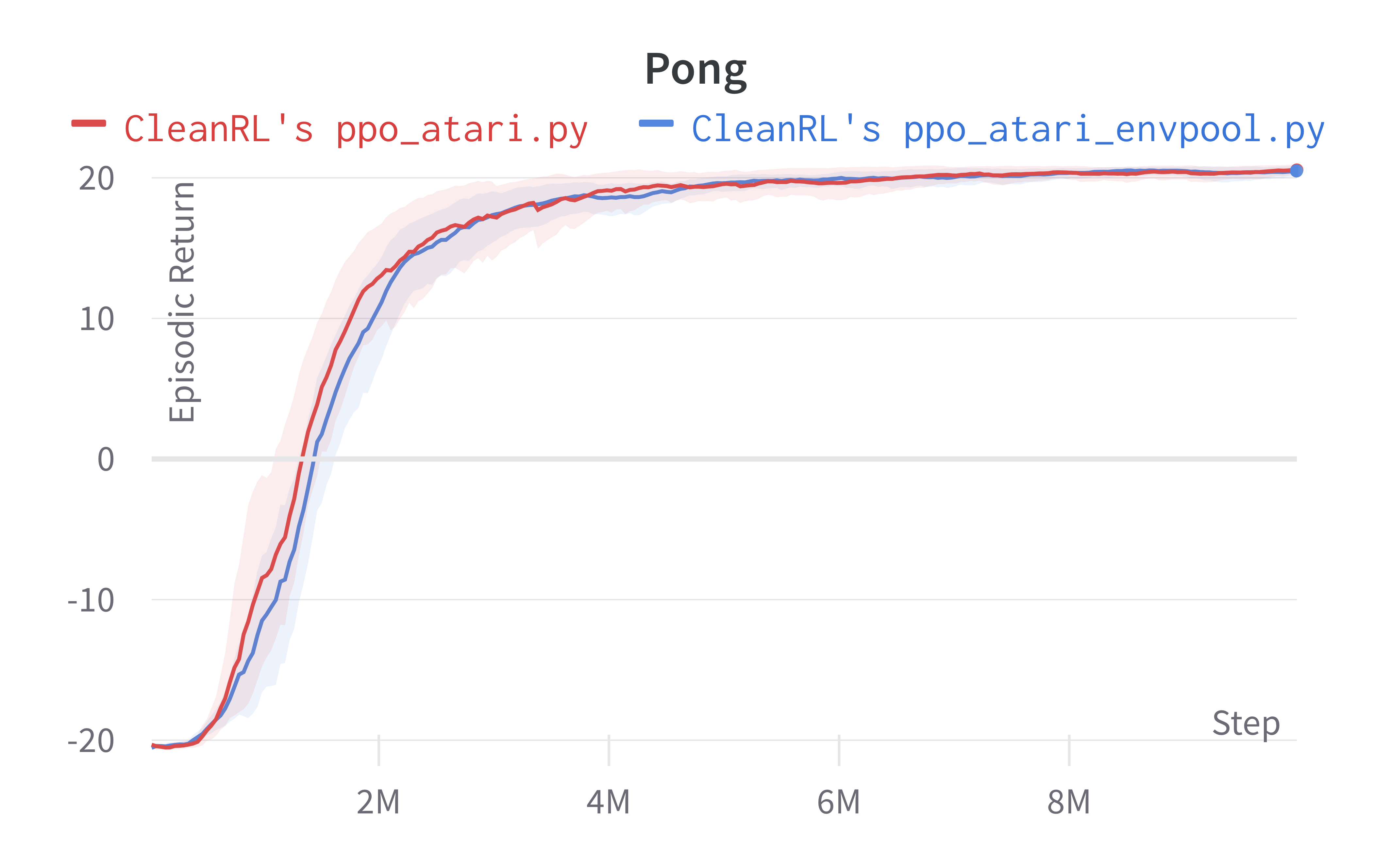
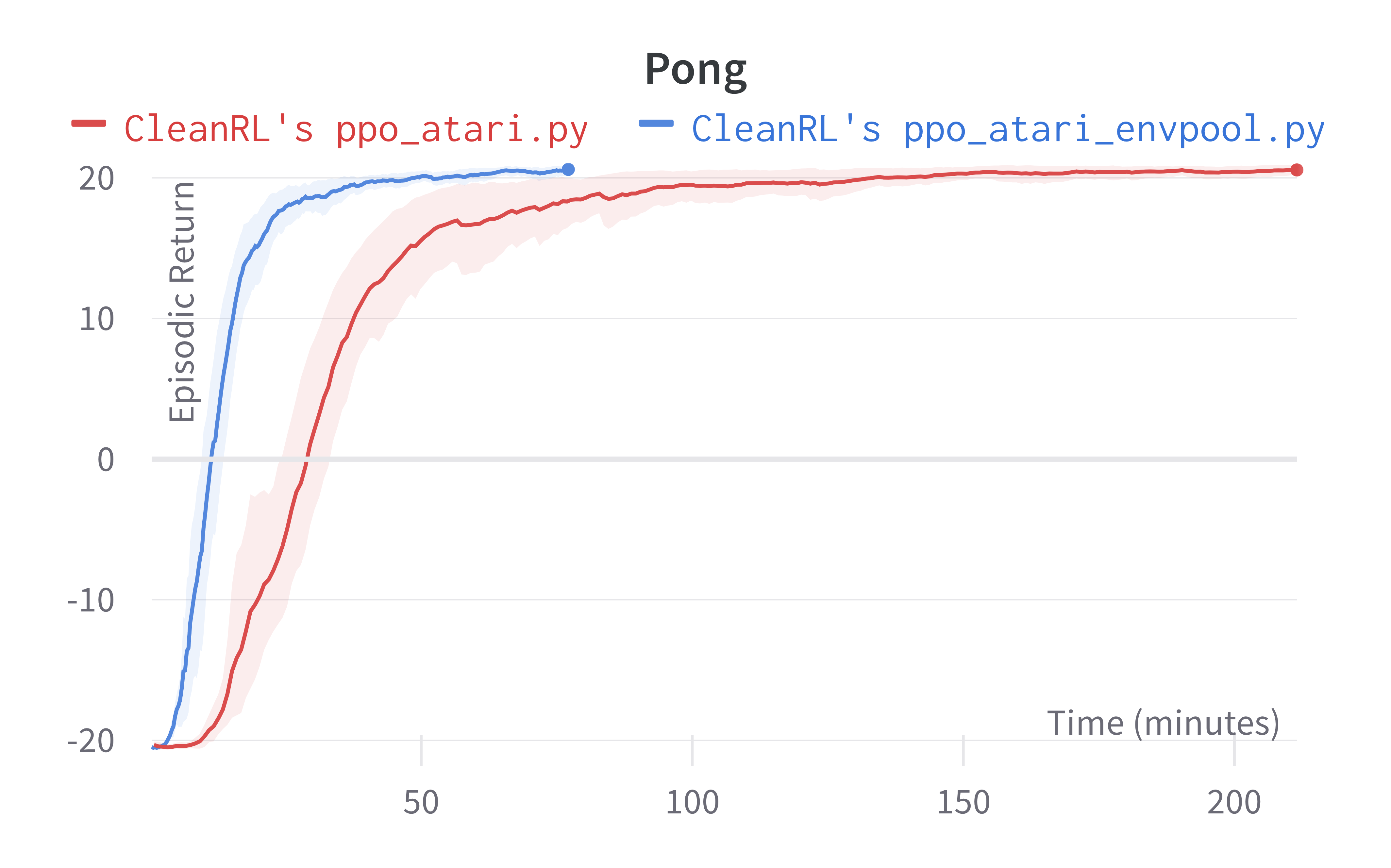
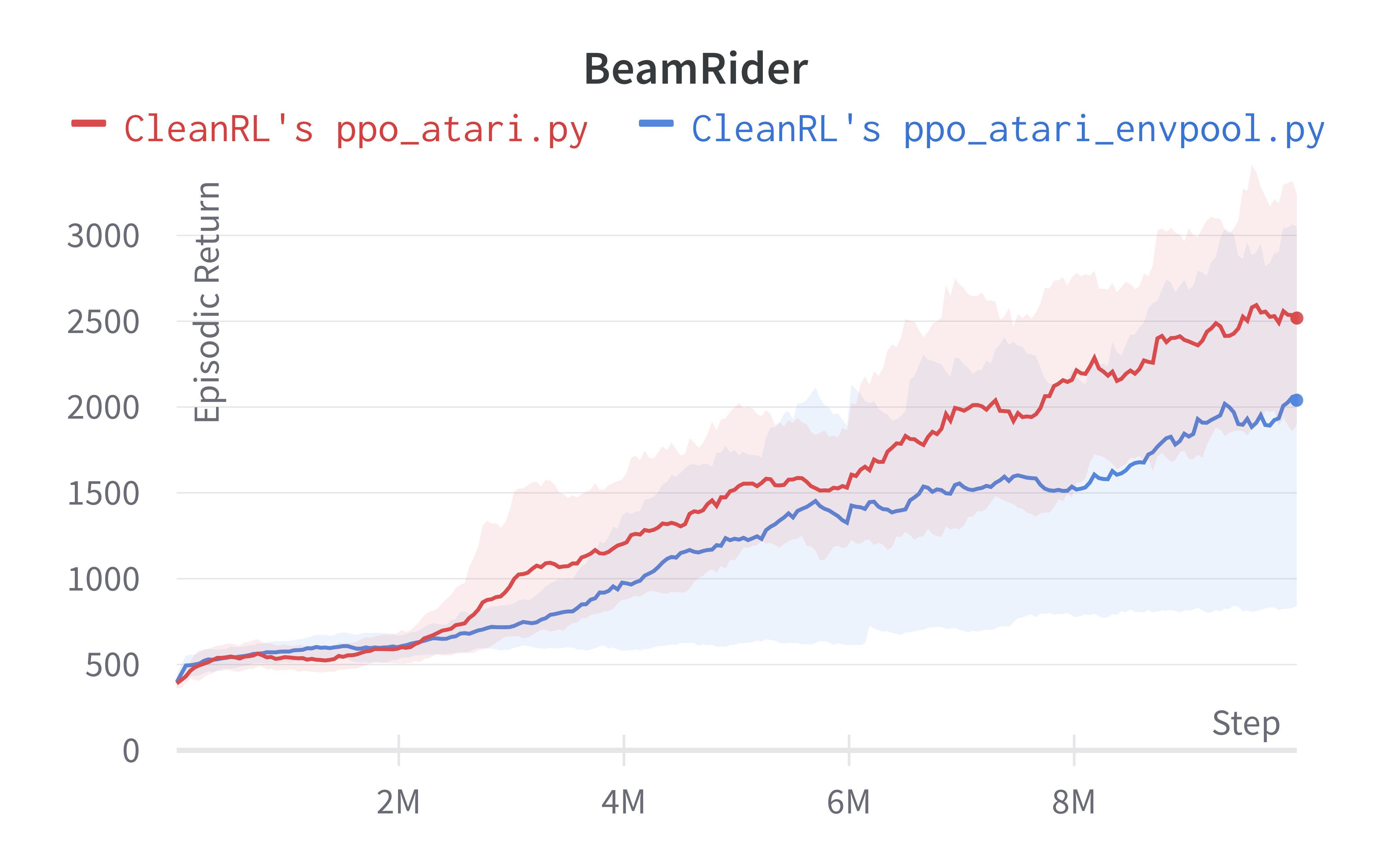
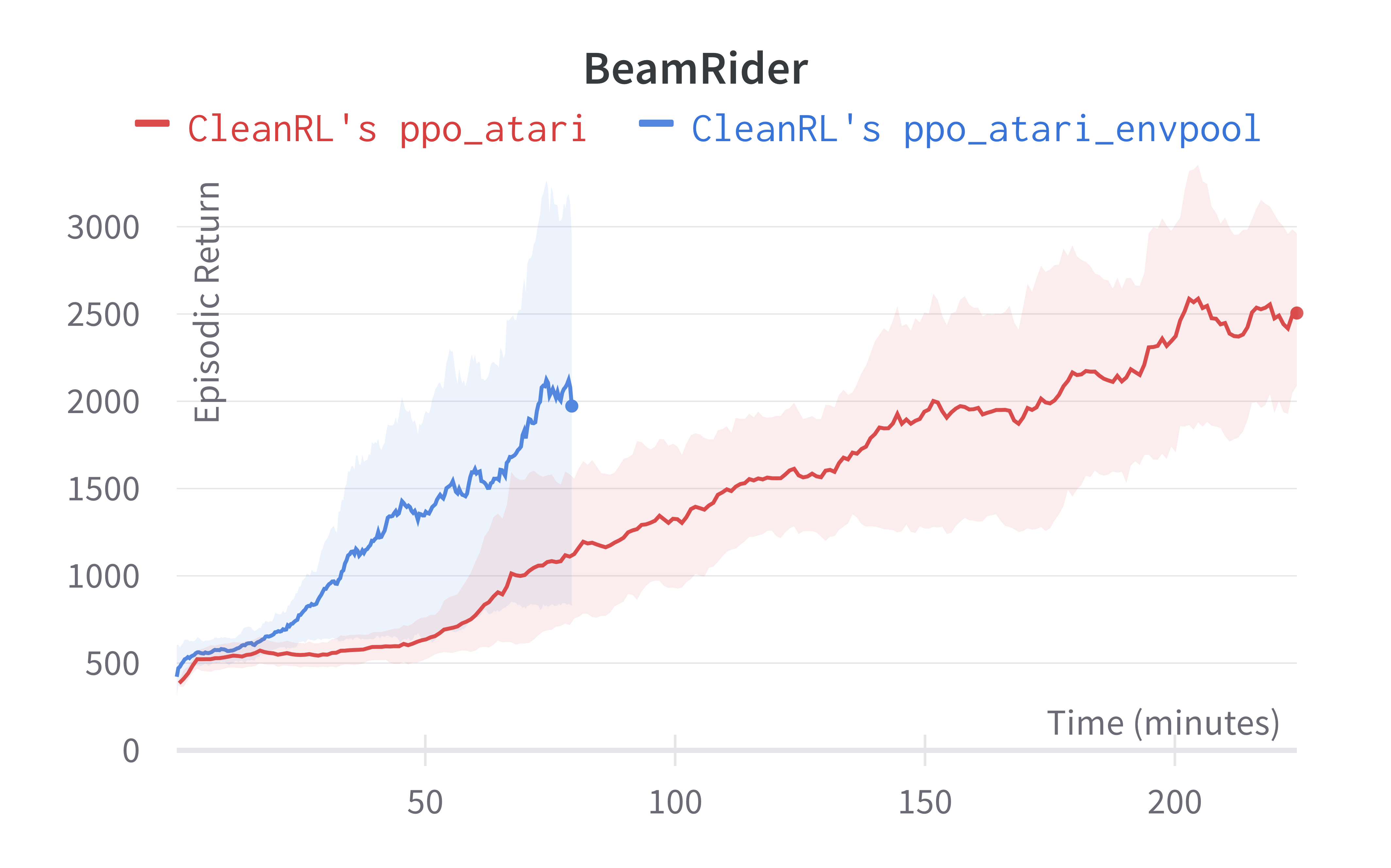
Tracked experiments and game play videos:
ppo_atari_envpool_xla_jax.py
The ppo_atari_envpool_xla_jax.py has the following features:
- Uses the blazing fast Envpool vectorized environment.
- Uses EnvPool's experimental XLA interface.
- Uses Jax, Flax, and Optax instead of
torch. - For Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Warning
Note that ppo_atari_envpool_xla_jax.py does not work in Windows and MacOs . See envpool's built wheels here: https://pypi.org/project/envpool/#files
Bug
EnvPool's vectorized environment does not behave the same as gym's vectorized environment, which causes a compatibility bug in our PPO implementation. When an action \(a\) results in an episode termination or truncation, the environment generates \(s_{last}\) as the terminated or truncated state; we then use \(s_{new}\) to denote the initial state of the new episodes. Here is how the bahviors differ:
- Under the vectorized environment of
envpool<=0.6.4, theobsinobs, reward, done, info = env.step(action)is the truncated state \(s_{last}\) - Under the vectorized environment of
gym==0.23.1, theobsinobs, reward, done, info = env.step(action)is the initial state \(s_{new}\).
This causes the \(s_{last}\) to be off by one. See sail-sg/envpool#194 for more detail. However, it does not seem to impact performance, so we take a note here and await for the upstream fix.
Usage
poetry install -E "envpool jax"
poetry run pip install --upgrade "jax[cuda]==0.3.17" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
python cleanrl/ppo_atari_envpool_xla_jax.py --help
python cleanrl/ppo_atari_envpool_xla_jax.py --env-id Breakout-v5
Explanation of the logged metrics
See related docs for ppo.py. In ppo_atari_envpool_xla_jax.py we omit logging losses/old_approx_kl and losses/clipfrac for brevity.
Additionally, we record the following metric:
charts/avg_episodic_return: the average value of the latest episodic returns ofargs.num_envs=8envscharts/avg_episodic_length: the average value of the latest episodic lengths ofargs.num_envs=8envs
Info
Note that we use charts/avg_episodic_return in place of charts/episodic_return and charts/episodic_length because under the EnvPool's XLA interface, we can only record fixed-shape metrics where as there could be a variable number of raw episodic returns / lengths. To resolve this challenge, we create variables (e.g., returned_episode_returns, returned_episode_lengths) to keep track of the latest episodic returns / lengths of each environment and average them for reporting purposes.
Implementation details
ppo_atari_envpool_xla_jax.py uses a customized RecordEpisodeStatistics to work with EnvPool's experimental XLA interface but has the same other implementation details as ppo_atari.py (see related docs) except that ppo_atari_envpool_xla_jax.py does not use the value function clipping for simplicity.
Info
We benchmarked the PPO implementation w/ and w/o value function clipping, finding no significant difference in performance, which is consistent with the findings in Andrychowicz et al.2. See the related report part 1 and part 2.

Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo_atari_envpool_xla_jax.py. Notice it has the same sample efficiency as ppo_atari.py, but runs about 3x faster.
Info
The following table and charts are generated by atari_hns_new.py, ours_vs_baselines_hns.py, and ours_vs_seedrl_hns.py.
| Environment | CleanRL ppo_atari_envpool_xla_jax.py | openai/baselines' PPO |
|---|---|---|
| Alien-v5 | 1744.76 | 1549.42 |
| Amidar-v5 | 617.137 | 546.406 |
| Assault-v5 | 5734.04 | 4050.78 |
| Asterix-v5 | 3341.9 | 3459.9 |
| Asteroids-v5 | 1669.3 | 1467.19 |
| Atlantis-v5 | 3.92929e+06 | 3.09748e+06 |
| BankHeist-v5 | 1192.68 | 1195.34 |
| BattleZone-v5 | 24937.9 | 20314.3 |
| BeamRider-v5 | 2447.84 | 2740.02 |
| Berzerk-v5 | 1082.72 | 887.019 |
| Bowling-v5 | 44.0681 | 62.2634 |
| Boxing-v5 | 92.0554 | 93.3596 |
| Breakout-v5 | 431.795 | 388.891 |
| Centipede-v5 | 2910.69 | 3688.16 |
| ChopperCommand-v5 | 5555.84 | 933.333 |
| CrazyClimber-v5 | 116114 | 111675 |
| Defender-v5 | 51439.2 | 50045.1 |
| DemonAttack-v5 | 22824.8 | 12173.9 |
| DoubleDunk-v5 | -8.56781 | -9 |
| Enduro-v5 | 1262.79 | 1061.12 |
| FishingDerby-v5 | 21.6222 | 23.8876 |
| Freeway-v5 | 33.1075 | 32.9167 |
| Frostbite-v5 | 904.346 | 924.5 |
| Gopher-v5 | 11369.6 | 2899.57 |
| Gravitar-v5 | 1141.95 | 870.755 |
| Hero-v5 | 24628.3 | 25984.5 |
| IceHockey-v5 | -4.91917 | -4.71505 |
| Jamesbond-v5 | 504.105 | 516.489 |
| Kangaroo-v5 | 7281.59 | 3791.5 |
| Krull-v5 | 9384.7 | 8672.95 |
| KungFuMaster-v5 | 26594.5 | 29116.1 |
| MontezumaRevenge-v5 | 0.240385 | 0 |
| MsPacman-v5 | 2461.62 | 2113.44 |
| NameThisGame-v5 | 5442.67 | 5713.89 |
| Phoenix-v5 | 14008.5 | 8693.21 |
| Pitfall-v5 | -0.0801282 | -1.47059 |
| Pong-v5 | 20.309 | 20.4043 |
| PrivateEye-v5 | 99.5283 | 21.2121 |
| Qbert-v5 | 16430.7 | 14283.4 |
| Riverraid-v5 | 8297.21 | 9267.48 |
| RoadRunner-v5 | 19342.2 | 40325 |
| Robotank-v5 | 15.45 | 16 |
| Seaquest-v5 | 1230.02 | 1754.44 |
| Skiing-v5 | -14684.3 | -13901.7 |
| Solaris-v5 | 2353.62 | 2088.12 |
| SpaceInvaders-v5 | 1162.16 | 1017.65 |
| StarGunner-v5 | 53535.9 | 40906 |
| Surround-v5 | -2.94558 | -6.08095 |
| Tennis-v5 | -15.0446 | -9.71429 |
| TimePilot-v5 | 6224.87 | 5775.53 |
| Tutankham-v5 | 238.419 | 197.929 |
| UpNDown-v5 | 430177 | 129459 |
| Venture-v5 | 0 | 115.278 |
| VideoPinball-v5 | 42975.3 | 32777.4 |
| WizardOfWor-v5 | 6247.83 | 5024.03 |
| YarsRevenge-v5 | 56696.7 | 8238.44 |
| Zaxxon-v5 | 6015.8 | 6379.79 |
Median Human Normalized Score (HNS) compared to openai/baselines.

Learning curves (left y-axis is the return and right y-axis is the human normalized score):

Percentage of human normalized score (HMS) for each game.

Info
Note the original openai/baselines uses atari-py==0.2.6 which hangs on gym.make("DefenderNoFrameskip-v4") and does not support SurroundNoFrameskip-v4 (see issue openai/atari-py#73). To get results on these environments, we use gym==0.23.1 ale-py==0.7.4 "AutoROM[accept-rom-license]==0.4.2 and manually register SurroundNoFrameskip-v4 in our fork.
Median Human Normalized Score (HNS) compared to SEEDRL's R2D2 (data available here).

Info
Note the SEEDRL's R2D2's median HNS data does not include learning curves for Defender and Surround (see google-research/seed_rl#78). Also note the SEEDRL's R2D2 uses slightly different Atari preprocessing than our ppo_atari_envpool_xla_jax.py, so we may be comparing apples and oranges; however, the results are still informative at the scale of 57 Atari games — we would be at least comparing similar apples.
Tracked experiments and game play videos:
ppo_procgen.py
The ppo_procgen.py has the following features:
- For the procgen environments
- Uses IMPALA-style neural network
- Works with the
Discreteaction space
Usage
poetry install --with procgen
python cleanrl/ppo_procgen.py --help
python cleanrl/ppo_procgen.py --env-id starpilot
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_procgen.py is based on the details in "Appendix" in The 37 Implementation Details of Proximal Policy Optimization, which are as follows:
- IMPALA-style Neural Network ( common/models.py#L28)
- Use the same
gammaparameter in theNormalizeRewardwrapper. Note that the original implementation from openai/train-procgen uses the defaultgamma=0.99in theVecNormalizewrapper butgamma=0.999as PPO's parameter. The mismatch between thegammas is technically incorrect. See #209
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
We try to match the default setting in openai/train-procgen except that we use the easy distribution mode and total_timesteps=25e6 to save compute. Notice openai/train-procgen has the following settings:
- Learning rate annealing is turned off by default
- Reward scaling and reward clipping is used
Below are the average episodic returns for ppo_procgen.py. To ensure the quality of the implementation, we compared the results against openai/baselies' PPO.
| Environment | ppo_procgen.py |
openai/baselies' PPO (Huang et al., 2022)1 |
|---|---|---|
| StarPilot (easy) | 32.47 ± 11.21 | 33.97 ± 7.86 |
| BossFight (easy) | 9.63 ± 2.35 | 9.35 ± 2.04 |
| BigFish (easy) | 16.80 ± 9.49 | 20.06 ± 5.34 |
Info
Note that we have run the procgen experiments using the easy distribution for reducing the computational cost.
Learning curves:
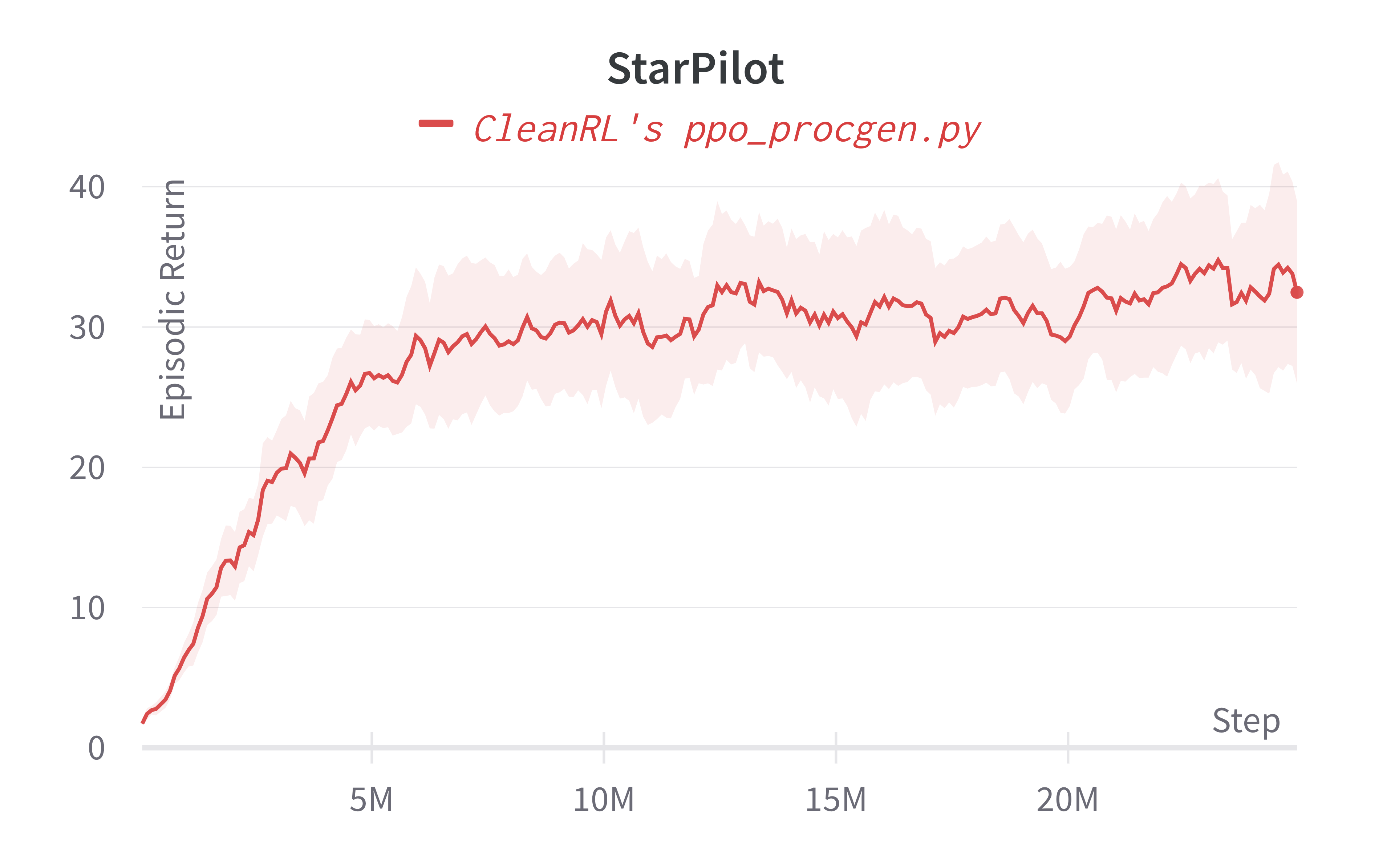
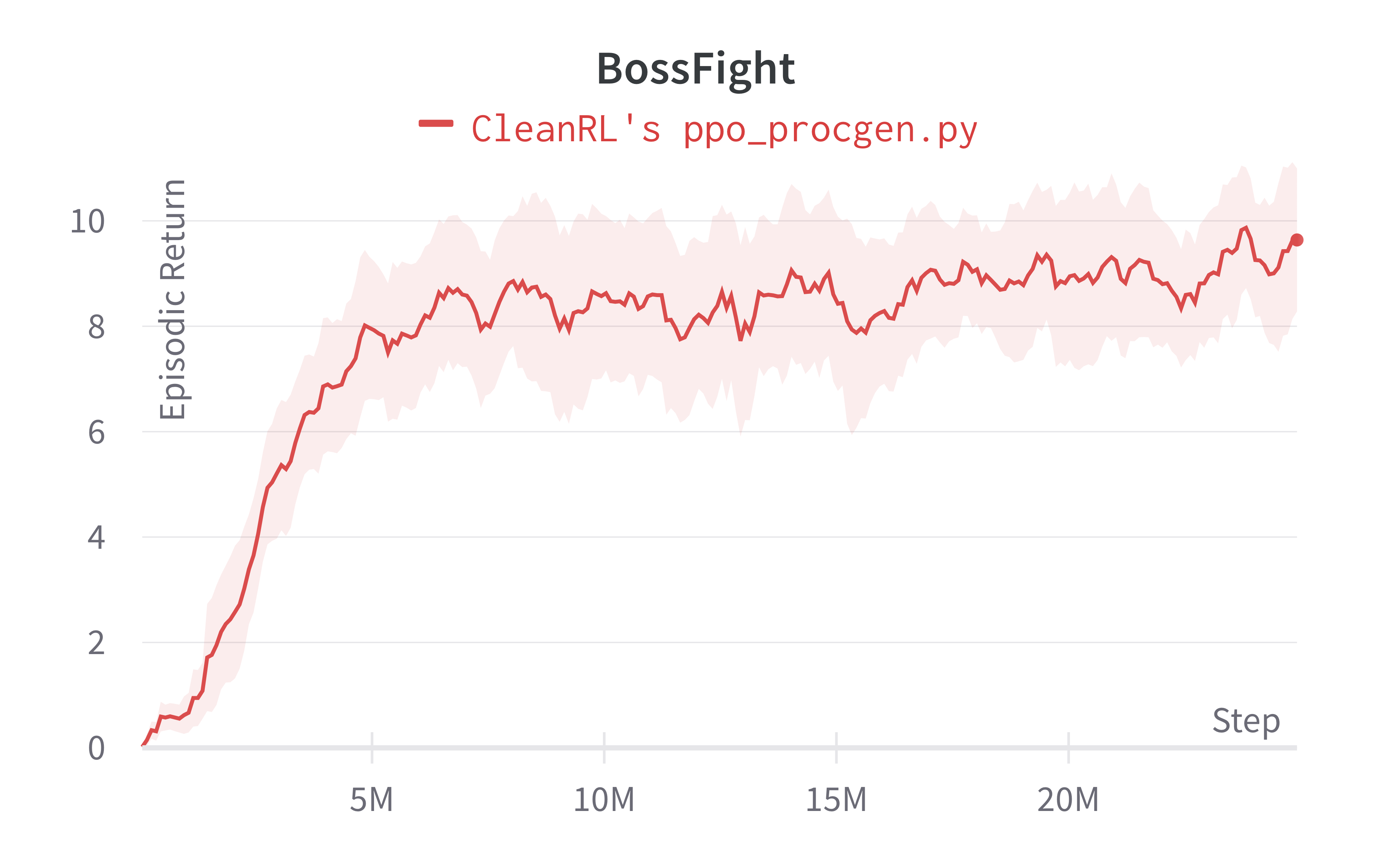
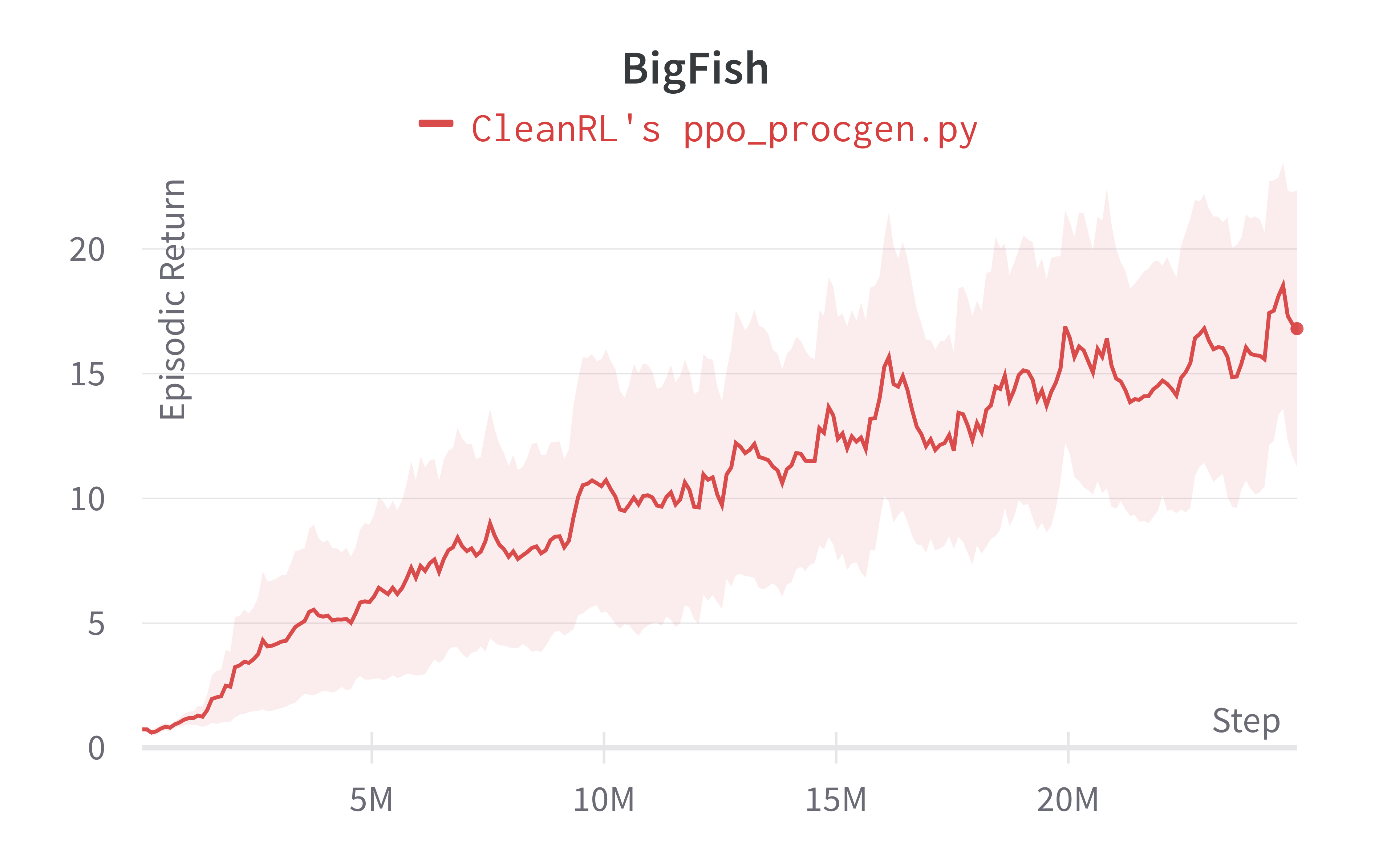
Tracked experiments and game play videos:
ppo_atari_multigpu.py
The ppo_atari_multigpu.py leverages data parallelism to speed up training time at no cost of sample efficiency.
ppo_atari_multigpu.py has the following features:
- Allows the users to use do training leveraging data parallelism
- For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Warning
Note that ppo_atari_multigpu.py does not work in Windows and MacOs . It will error out with NOTE: Redirects are currently not supported in Windows or MacOs. See pytorch/pytorch#20380
Usage
poetry install --with atari
python cleanrl/ppo_atari_multigpu.py --help
# `--nproc_per_node=2` specifies how many subprocesses we spawn for training with data parallelism
# note it is possible to run this with a *single GPU*: each process will simply share the same GPU
torchrun --standalone --nnodes=1 --nproc_per_node=2 cleanrl/ppo_atari_multigpu.py --env-id BreakoutNoFrameskip-v4
# by default we use the `gloo` backend, but you can use the `nccl` backend for better multi-GPU performance
torchrun --standalone --nnodes=1 --nproc_per_node=2 cleanrl/ppo_atari_multigpu.py --env-id BreakoutNoFrameskip-v4 --backend nccl
# it is possible to spawn more processes than the amount of GPUs you have via `--device-ids`
# e.g., the command below spawns two processes using GPU 0 and two processes using GPU 1
torchrun --standalone --nnodes=1 --nproc_per_node=2 cleanrl/ppo_atari_multigpu.py --env-id BreakoutNoFrameskip-v4 --device-ids 0 0 1 1
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
ppo_atari_multigpu.py is based on ppo_atari.py (see its related docs).
We use Pytorch's distributed API to implement the data parallelism paradigm. The basic idea is that the user can spawn \(N\) processes each holding a copy of the model, step the environments, and averages their gradients together for the backward pass. Here are a few note-worthy implementation details.
- Shard the environments: by default,
ppo_atari_multigpu.pyuses--num-envs=8. When callingtorchrun --standalone --nnodes=1 --nproc_per_node=2 cleanrl/ppo_atari_multigpu.py --env-id BreakoutNoFrameskip-v4, it spawns \(N=2\) (by--nproc_per_node=2) subprocesses and shard the environments across these 2 subprocesses. In particular, each subprocess will have8/2=4environments. Implementation wise, we doargs.num_envs = int(args.num_envs / world_size). Hereworld_size=2refers to the size of the world, which means the group of subprocesses. We also need to adjust various variables as follows:- batch size: by default it is
(num_envs * num_steps) = 8 * 128 = 1024and we adjust it to(num_envs / world_size * num_steps) = (4 * 128) = 512. - minibatch size: by default it is
(num_envs * num_steps) / num_minibatches = (8 * 128) / 4 = 256and we adjust it to(num_envs / world_size * num_steps) / num_minibatches = (4 * 128) / 4 = 128. - number of updates: by default it is
total_timesteps // batch_size = 10000000 // (8 * 128) = 9765and we adjust it tototal_timesteps // (batch_size * world_size) = 10000000 // (8 * 128 * 2) = 4882. - global step increment: by default it is
num_envsand we adjust it tonum_envs * world_size.
- batch size: by default it is
-
Adjust seed per process: we need be very careful with seeding: we could have used the exact same seed for each subprocess. To ensure this does not happen, we do the following
# CRUCIAL: note that we needed to pass a different seed for each data parallelism worker args.seed += local_rank random.seed(args.seed) np.random.seed(args.seed) torch.manual_seed(args.seed - local_rank) torch.backends.cudnn.deterministic = args.torch_deterministic # ... envs = gym.vector.SyncVectorEnv( [make_env(args.env_id, args.seed + i, i, args.capture_video, run_name) for i in range(args.num_envs)] ) assert isinstance(envs.single_action_space, gym.spaces.Discrete), "only discrete action space is supported" agent = Agent(envs).to(device) torch.manual_seed(args.seed) optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)Notice that we adjust the seed with
args.seed += local_rank(line 2), wherelocal_rankis the index of the subprocesses. This ensures we seed packages and envs with uncorrealted seeds. However, we do need to use the sametorchseed for all process to initialize same weights for theagent(line 5), after which we can use a different seed fortorch(line 16). 1. Efficient gradient averaging: PyTorch recommends to average the gradient across the whole world via the following (see docs)for param in agent.parameters(): dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM) param.grad.data /= world_sizeHowever, @cswinter introduces a more efficient gradient averaging scheme with proper batching (see entity-neural-network/incubator#220), which looks like:
all_grads_list = [] for param in agent.parameters(): if param.grad is not None: all_grads_list.append(param.grad.view(-1)) all_grads = torch.cat(all_grads_list) dist.all_reduce(all_grads, op=dist.ReduceOp.SUM) offset = 0 for param in agent.parameters(): if param.grad is not None: param.grad.data.copy_( all_grads[offset : offset + param.numel()].view_as(param.grad.data) / world_size ) offset += param.numel()In our previous empirical testing (see vwxyzjn/cleanrl#162), we have found @cswinter's implementation to be faster, hence we adopt it in our implementation.
We can see how ppo_atari_multigpu.py can result in no loss of sample efficiency. In this example, the ppo_atari.py's minibatch size is 256 and the ppo_atari_multigpu.py's minibatch size is 128 with world size 2. Because we average gradient across the world, the gradient under ppo_atari_multigpu.py should be virtually the same as the gradient under ppo_atari.py.
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Below are the average episodic returns for ppo_atari_multigpu.py. To ensure no loss of sample efficiency, we compared the results against ppo_atari.py.
| Environment | ppo_atari_multigpu.py (in ~160 mins) |
ppo_atari.py (in ~215 mins) |
|---|---|---|
| BreakoutNoFrameskip-v4 | 429.06 ± 52.09 | 416.31 ± 43.92 |
| PongNoFrameskip-v4 | 20.40 ± 0.46 | 20.59 ± 0.35 |
| BeamRiderNoFrameskip-v4 | 2454.54 ± 740.49 | 2445.38 ± 528.91 |
Learning curves:
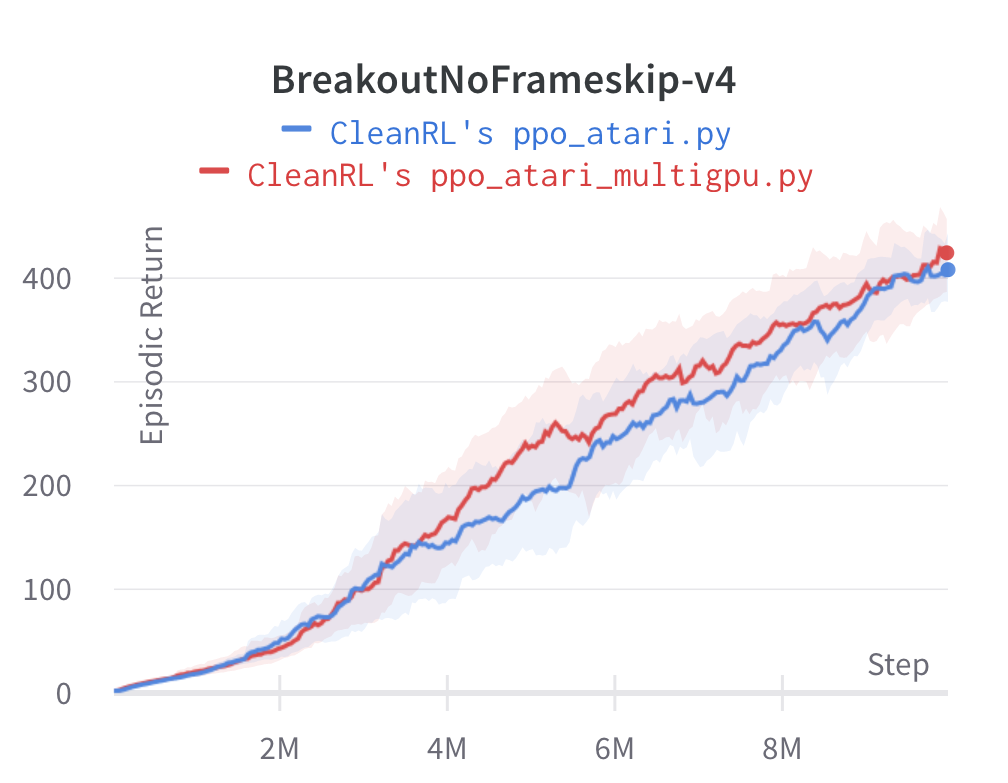
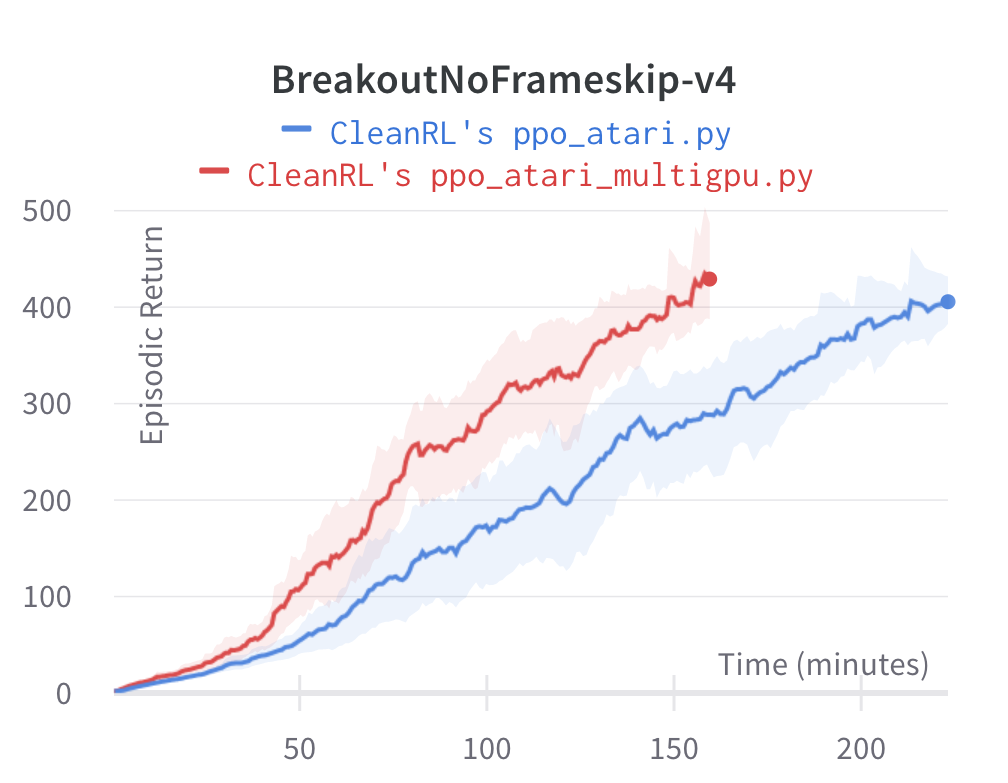
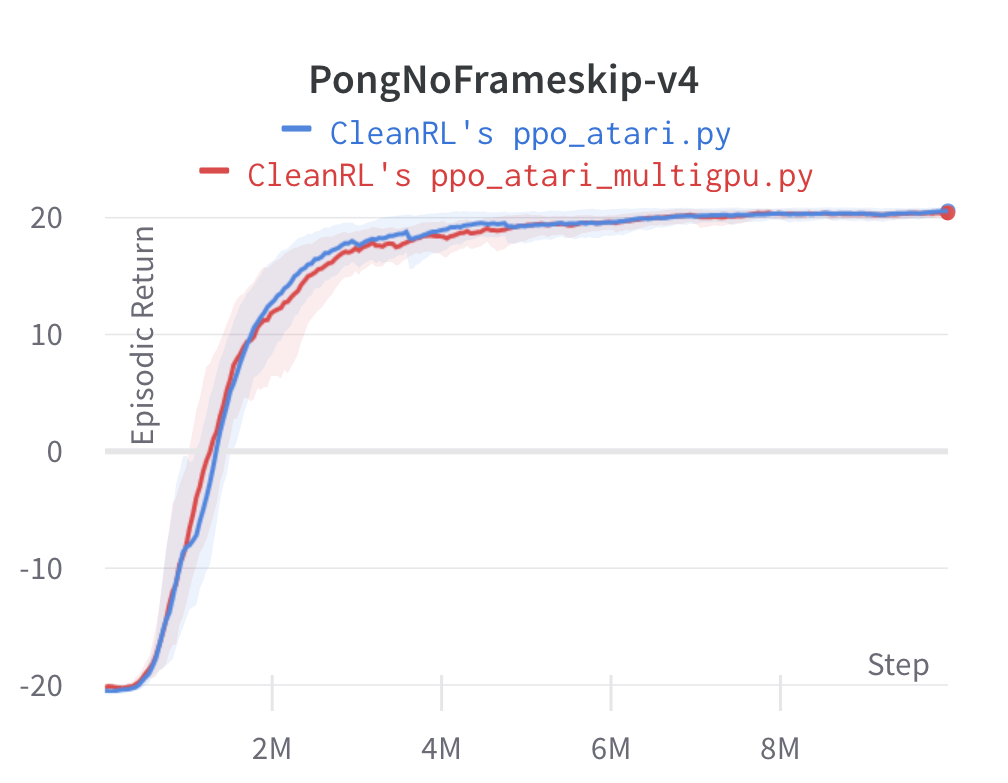
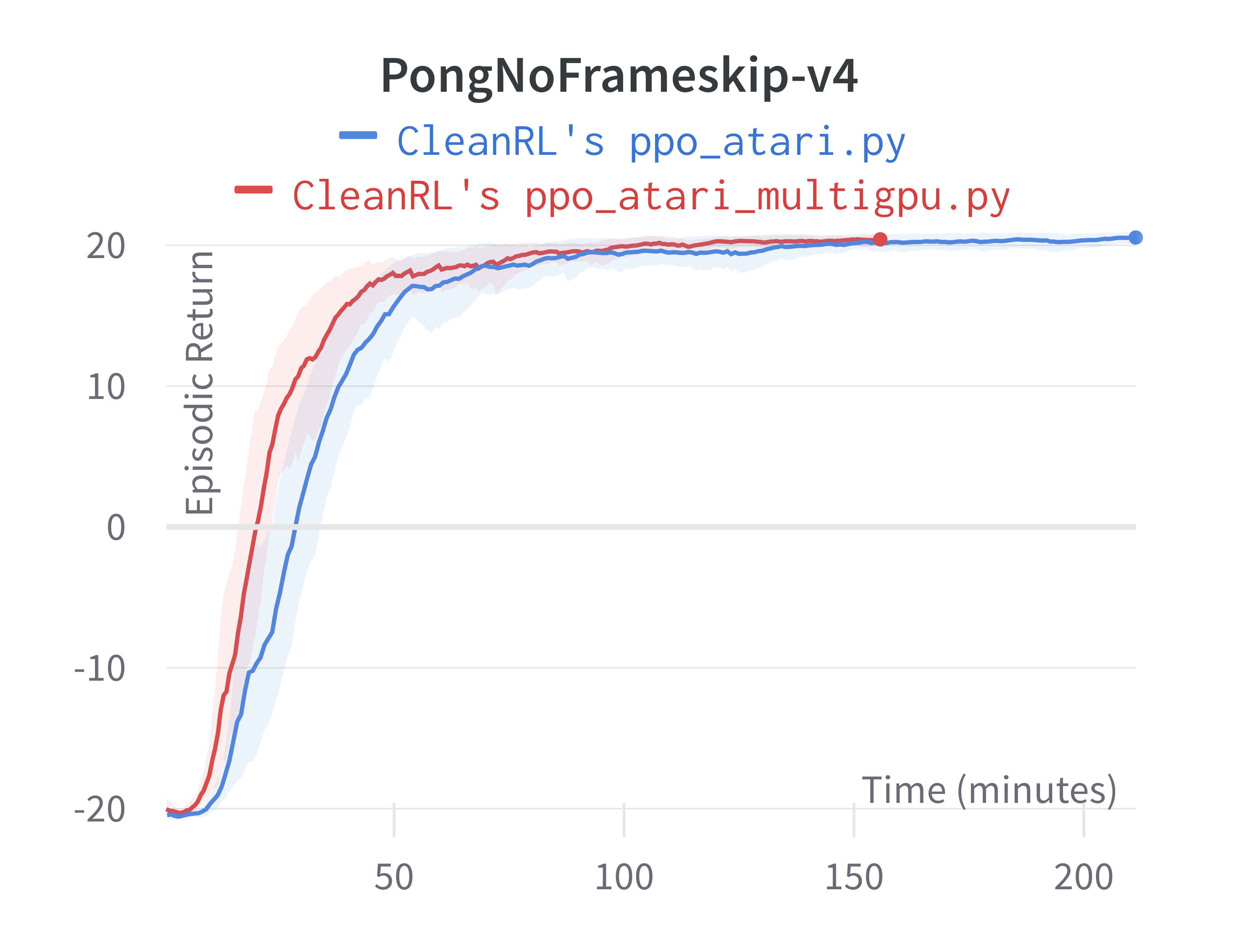
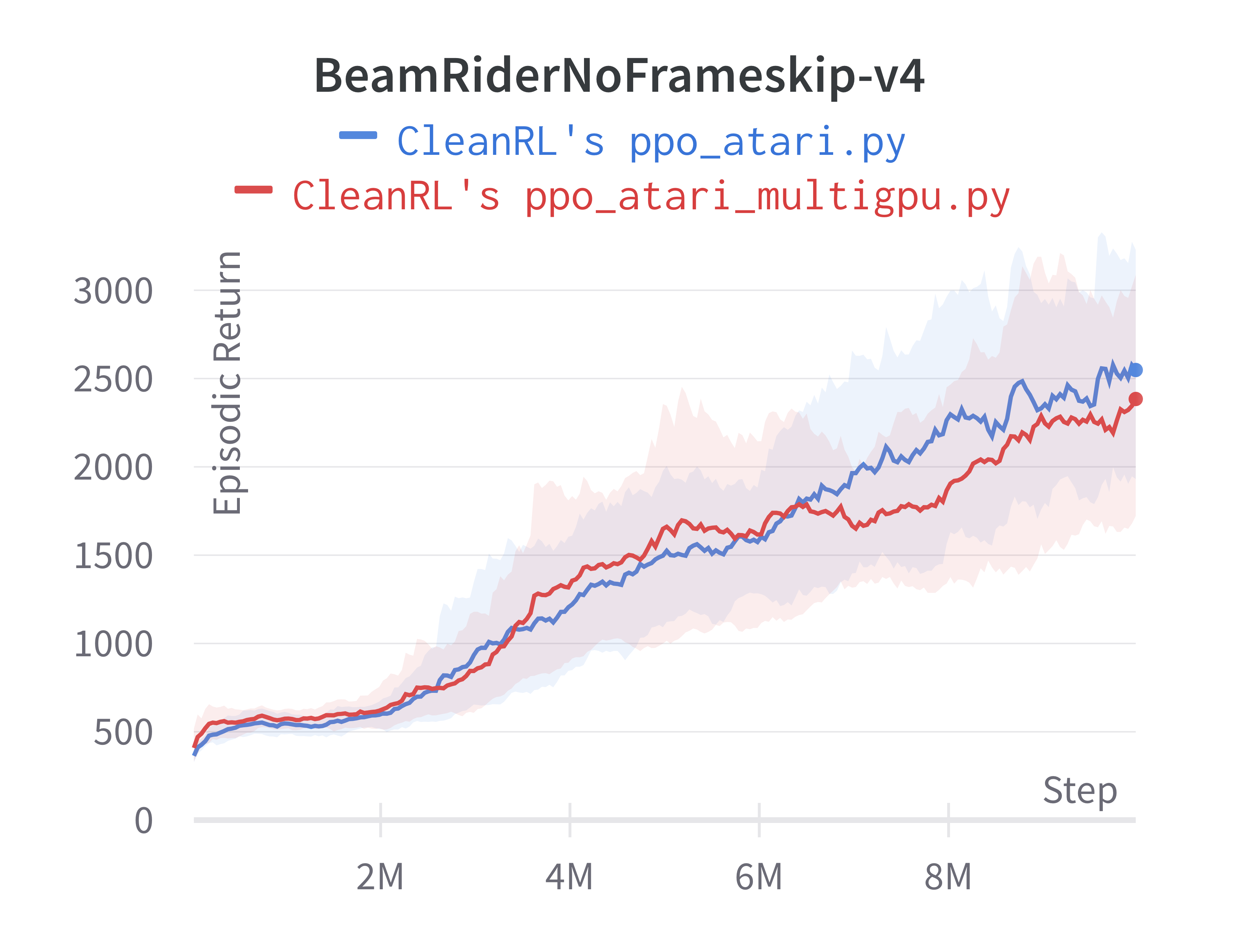
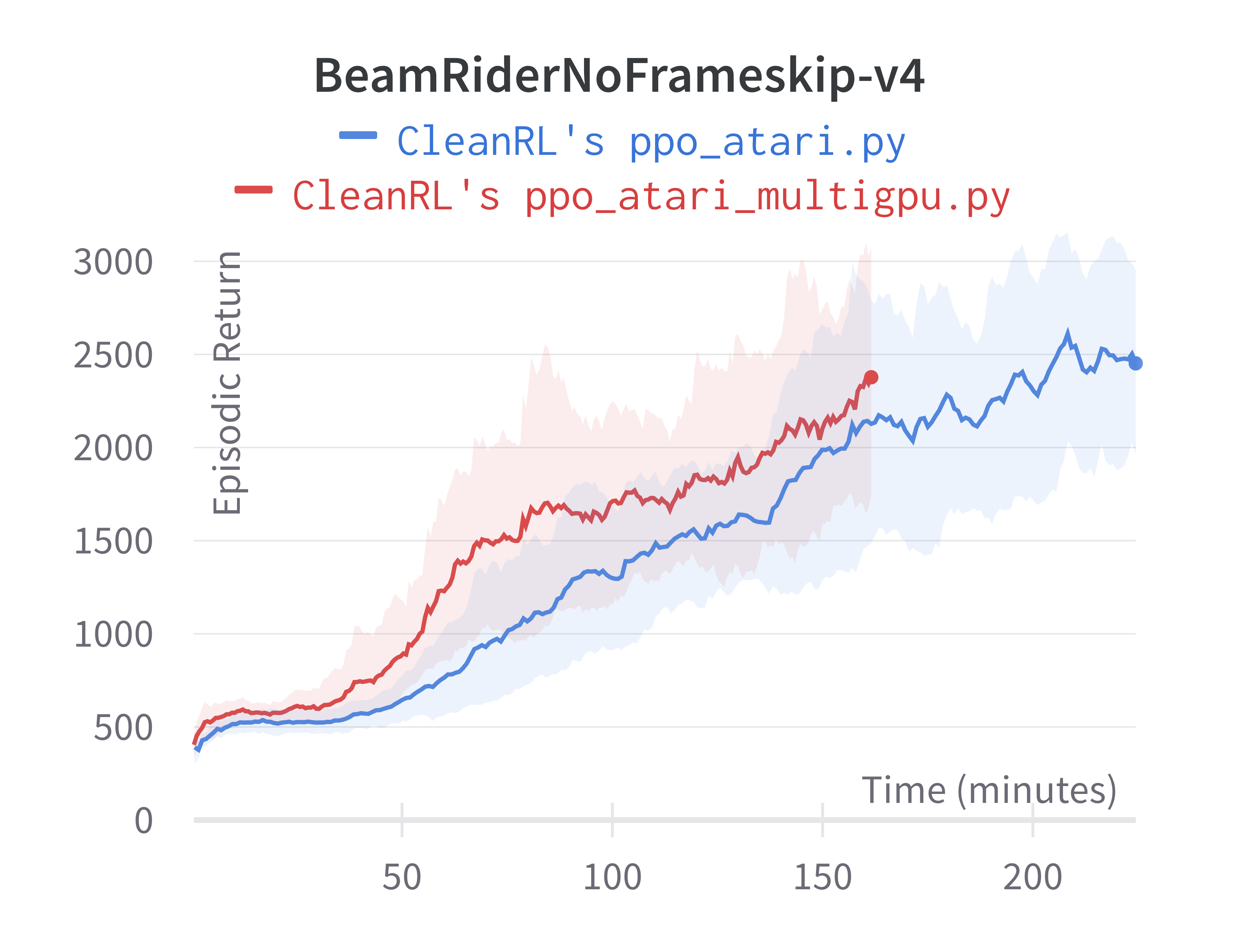
Under the same hardware, we see that ppo_atari_multigpu.py is about 30% faster than ppo_atari.py with no loss of sample efficiency.
Info
Although ppo_atari_multigpu.py is 30% faster than ppo_atari.py, ppo_atari_multigpu.py is still slower than ppo_atari_envpool.py, as shown below. This comparison really highlights the different kinds of optimization possible.
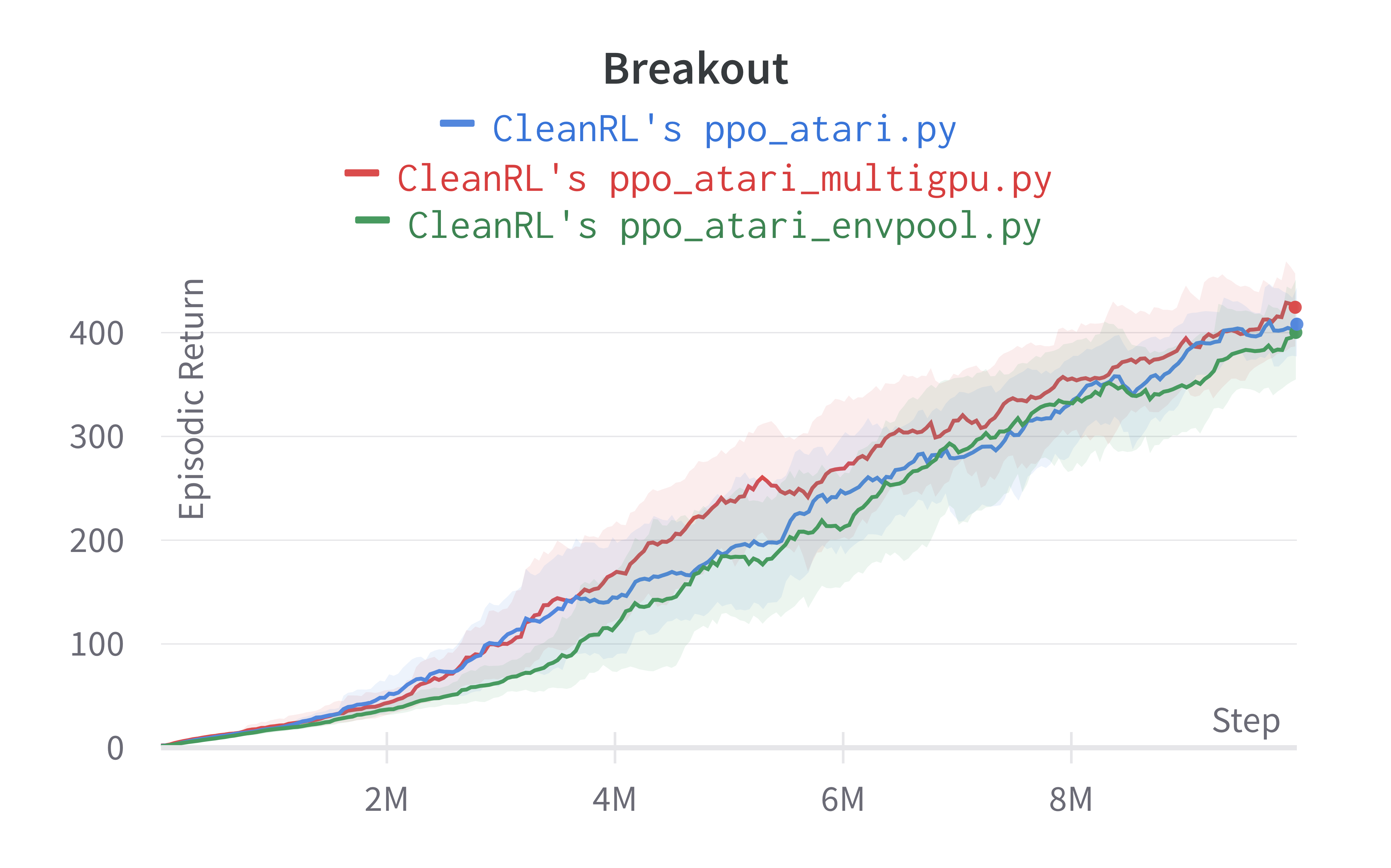
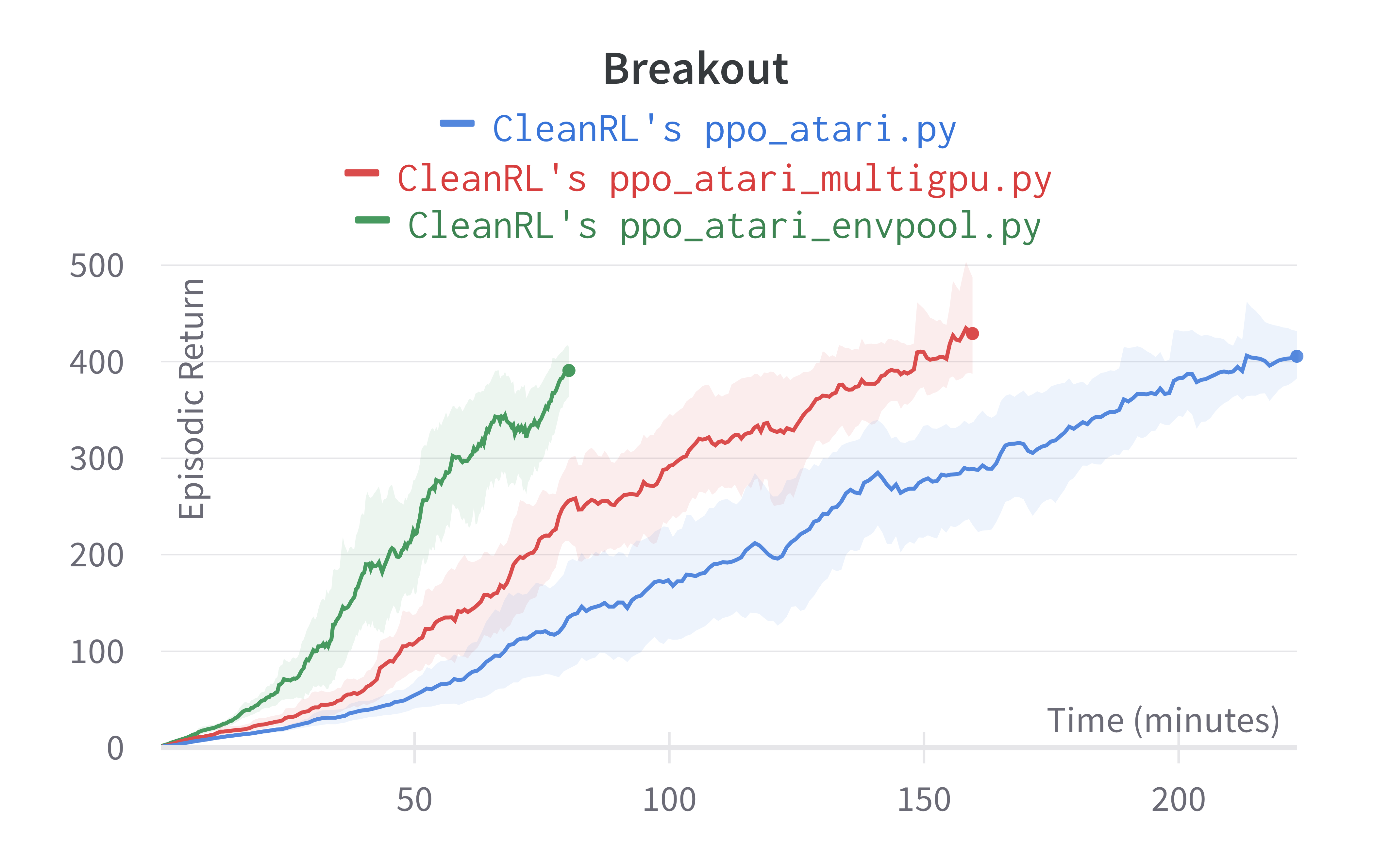
The purpose of ppo_atari_multigpu.py is not (yet) to achieve the fastest PPO + Atari example. Rather, its purpose is to rigorously validate data paralleism does provide performance benefits. We could do something like ppo_atari_multigpu_envpool.py to possibly obtain the fastest PPO + Atari possible, but that is for another day. Note we may need numba to pin the threads envpool is using in each subprocess to avoid threads fighting each other and lowering the throughput.
Tracked experiments and game play videos:
ppo_pettingzoo_ma_atari.py
ppo_pettingzoo_ma_atari.py trains an agent to learn playing Atari games via selfplay. The selfplay environment is implemented as a vectorized environment from PettingZoo.ml. The basic idea is to create vectorized environment \(E\) with num_envs = N, where \(N\) is the number of players in the game. Say \(N = 2\), then the 0-th sub environment of \(E\) will return the observation for player 0 and 1-th sub environment will return the observation of player 1. Then the two environments takes a batch of 2 actions and execute them for player 0 and player 1, respectively. See "Vectorized architecture" in The 37 Implementation Details of Proximal Policy Optimization for more detail.
ppo_pettingzoo_ma_atari.py has the following features:
- For playing the pettingzoo's multi-agent Atari game.
- Works with the pixel-based observation space
- Works with the
Boxaction space
Warning
Note that ppo_pettingzoo_ma_atari.py does not work in Windows . See https://pypi.org/project/multi-agent-ale-py/#files
Usage
poetry install --with pettingzoo,atari
poetry run AutoROM --accept-license
python cleanrl/ppo_pettingzoo_ma_atari.py --help
python cleanrl/ppo_pettingzoo_ma_atari.py --env-id pong_v3
python cleanrl/ppo_pettingzoo_ma_atari.py --env-id surround_v2
See https://www.pettingzoo.ml/atari for a full-list of supported environments such as basketball_pong_v3. Notice pettingzoo sometimes introduces breaking changes, so make sure to install the pinned dependencies via poetry.
Explanation of the logged metrics
Additionally, it logs the following metrics
charts/episodic_return-player0: episodic return of the game for player 0charts/episodic_return-player1: episodic return of the game for player 1charts/episodic_length-player0: episodic length of the game for player 0charts/episodic_length-player1: episodic length of the game for player 1
See other logged metrics in the related docs for ppo.py.
Implementation details
ppo_pettingzoo_ma_atari.py is based on ppo_atari.py (see its related docs).
ppo_pettingzoo_ma_atari.py additionally has the following implementation details:
-
supersuitwrappers: uses preprocessing wrappers fromsupersuitinstead of fromstable_baselines3, which looks like the following. In particular note that thesupersuitdoes not offer a wrapper similar toNoopResetEnv, and that it uses theagent_indicator_v0to add two channels indicating the which player the agent controls.1. A more detailed note on the-env = gym.make(env_id) -env = NoopResetEnv(env, noop_max=30) -env = MaxAndSkipEnv(env, skip=4) -env = EpisodicLifeEnv(env) -if "FIRE" in env.unwrapped.get_action_meanings(): - env = FireResetEnv(env) -env = ClipRewardEnv(env) -env = gym.wrappers.ResizeObservation(env, (84, 84)) -env = gym.wrappers.GrayScaleObservation(env) -env = gym.wrappers.FrameStack(env, 4) +env = importlib.import_module(f"pettingzoo.atari.{args.env_id}").parallel_env() +env = ss.max_observation_v0(env, 2) +env = ss.frame_skip_v0(env, 4) +env = ss.clip_reward_v0(env, lower_bound=-1, upper_bound=1) +env = ss.color_reduction_v0(env, mode="B") +env = ss.resize_v1(env, x_size=84, y_size=84) +env = ss.frame_stack_v1(env, 4) +env = ss.agent_indicator_v0(env, type_only=False) +env = ss.pettingzoo_env_to_vec_env_v1(env) +envs = ss.concat_vec_envs_v1(env, args.num_envs // 2, num_cpus=0, base_class="gym")agent_indicator_v0wrapper: let's dig deeper into howagent_indicator_v0works. We doprint(envs.reset(), envs.reset().shape)[ 0., 0., 0., 236., 1, 0.]], [[ 0., 0., 0., 236., 0., 1.], [ 0., 0., 0., 236., 0., 1.], [ 0., 0., 0., 236., 0., 1.], ..., [ 0., 0., 0., 236., 0., 1.], [ 0., 0., 0., 236., 0., 1.], [ 0., 0., 0., 236., 0., 1.]]]]) torch.Size([16, 84, 84, 6])So the
agent_indicator_v0adds the last two columns, where[ 0., 0., 0., 236., 1, 0.]]means this observation is for player 0, and[ 0., 0., 0., 236., 0., 1.]is for player 1. Notice the observation still has the range of \([0, 255]\) but the agent indicator channel has the range of \([0,1]\), so we need to be careful when dividing the observation by 255. In particular, we would only divide the first four channels by 255 and leave the agent indicator channels untouched as follows:def get_action_and_value(self, x, action=None): x = x.clone() x[:, :, :, [0, 1, 2, 3]] /= 255.0 hidden = self.network(x.permute((0, 3, 1, 2)))
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
Info
Note that evaluation is usually tricker in in selfplay environments. The usual episodic return is not a good indicator of the agent's performance in zero-sum games because the episodic return converges to zero. To evaluate the agent's ability, an intuitive approach is to take a look at the videos of the agents playing the game (included below), visually inspect the agent's behavior. The best scheme, however, is rating systems like Trueskill or ELO scores. However, they are more difficult to implement and are outside the scode of ppo_pettingzoo_ma_atari.py.
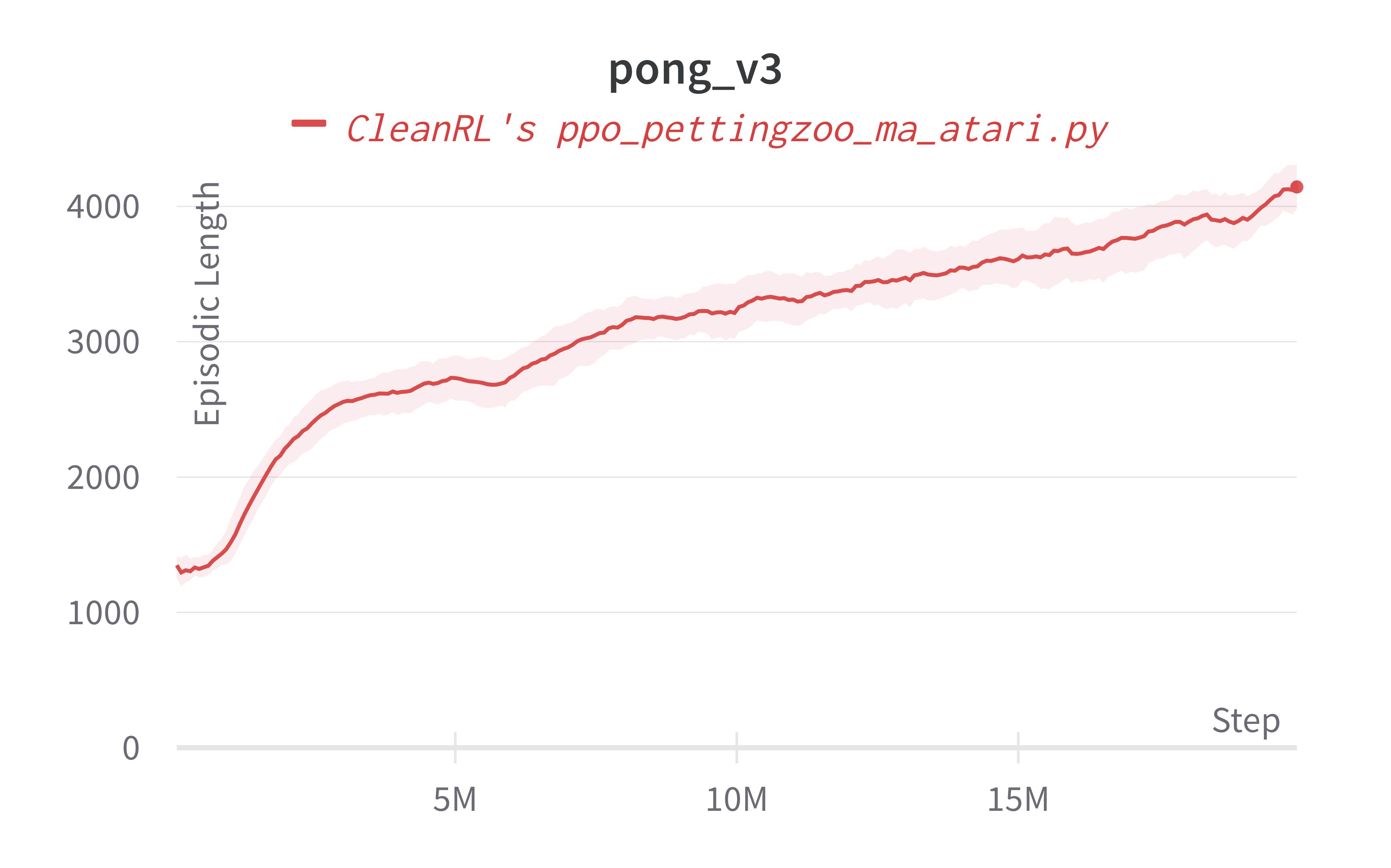
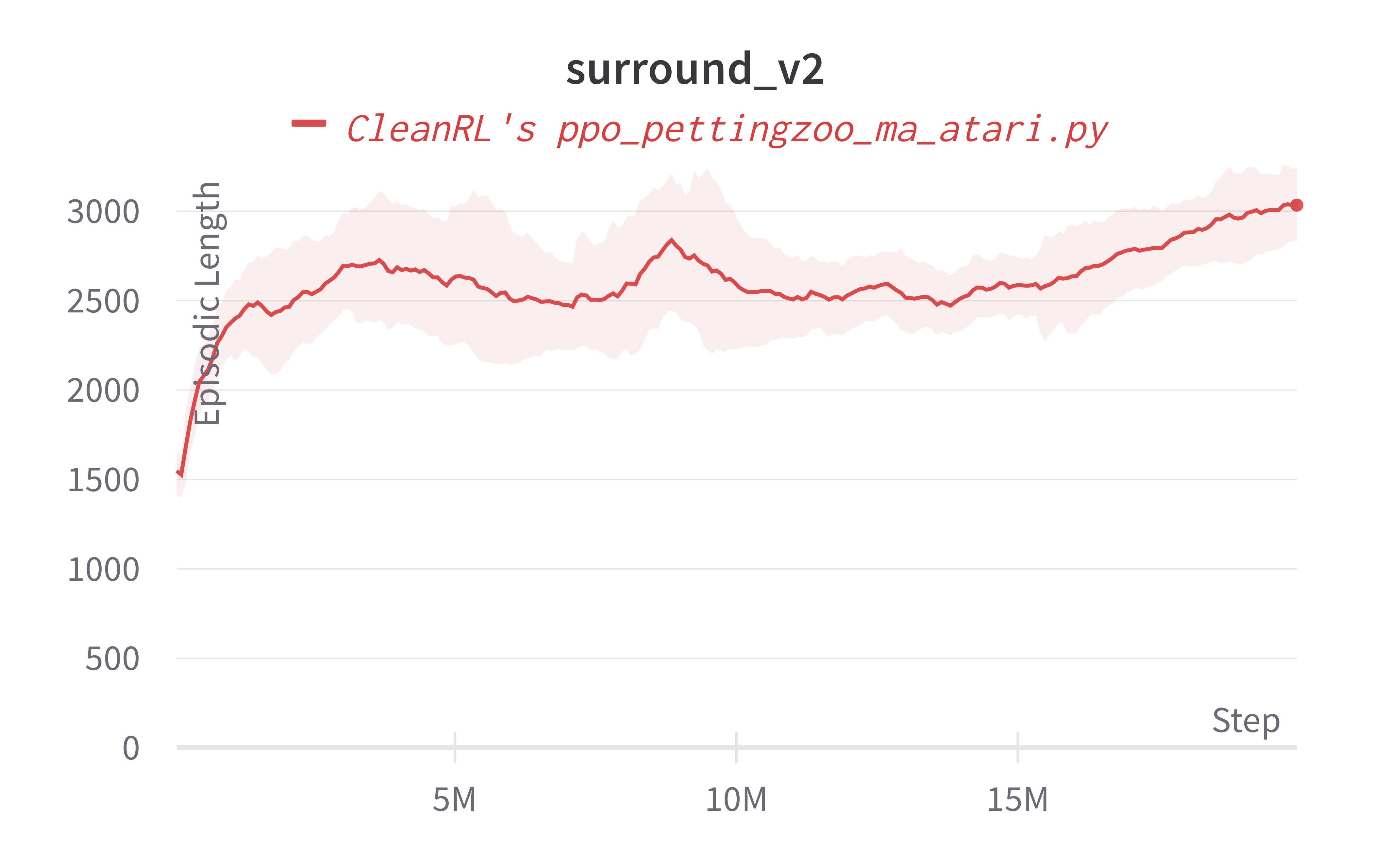
For simplicity, we measure the episodic length instead, which in a sense measures how many "back and forth" the agent can create. In other words, the longer the agent can play the game, the better the agent can play. Empirically, we have found episodic length to be a good indicator of the agent's skill, especially in pong_v3 and surround_v2. However, it is not the case for tennis_v3 and we'd need to visually inspect the agents' game play videos.
Below are the average episodic length for ppo_pettingzoo_ma_atari.py. To ensure no loss of sample efficiency, we compared the results against ppo_atari.py.
| Environment | ppo_pettingzoo_ma_atari.py |
|---|---|
| pong_v3 | 4153.60 ± 190.80 |
| surround_v2 | 3055.33 ± 223.68 |
| tennis_v3 | 14538.02 ± 7005.54 |
Learning curves:
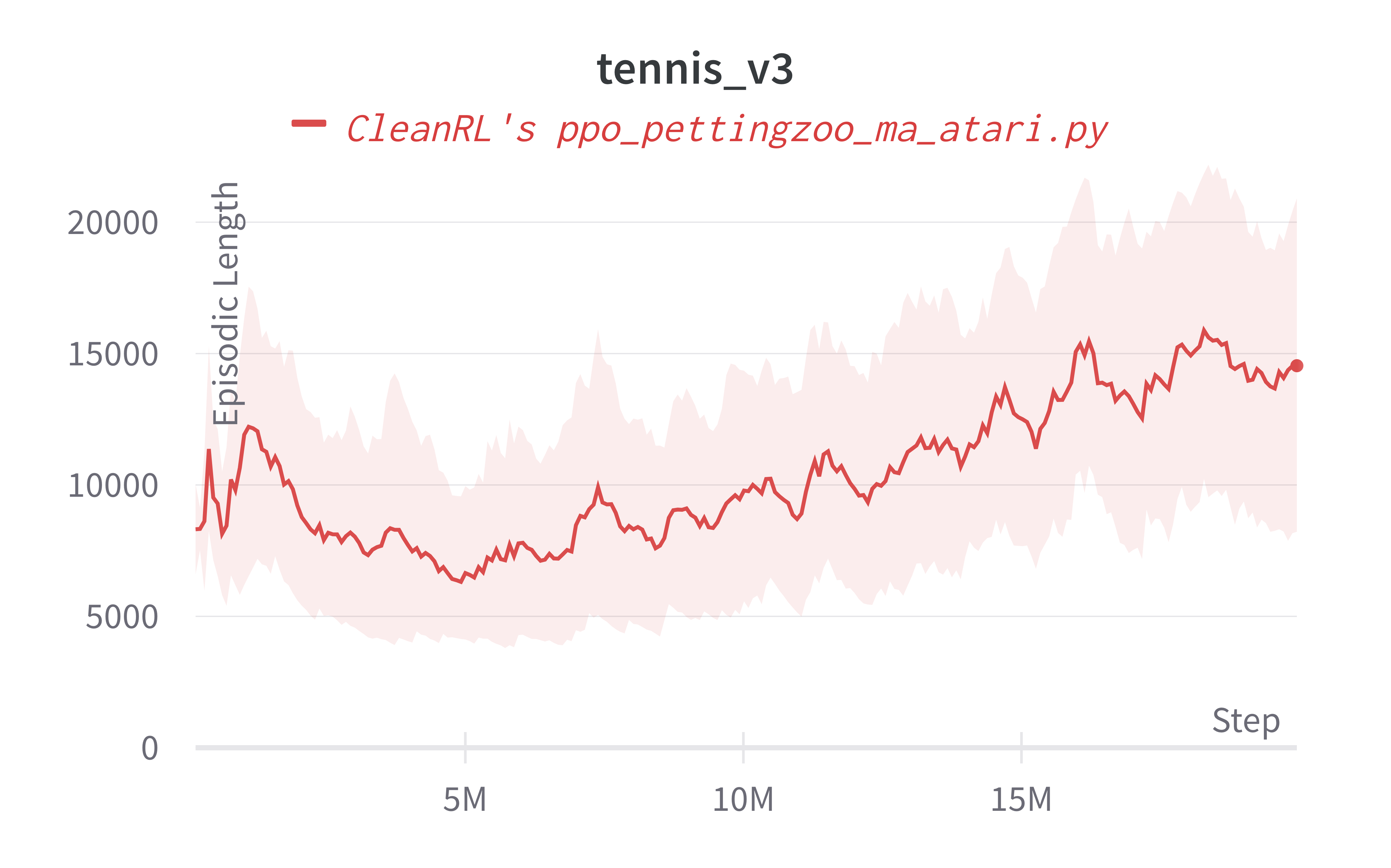
Tracked experiments and game play videos:
ppo_continuous_action_isaacgym.py
Experimental
The ppo_continuous_action_isaacgym.py has the following features:
- Works with IsaacGymEnvs.
- Works with the
Boxobservation space of low-level features - Works with the
Box(continuous) action space
IsaacGymEnvs is a hardware-accelerated (or GPU-accelerated) robotics simulation environment based on torch, which allows us to run thousands of simulation environments at the same time, empowering RL agents to learn many MuJoCo-style robotics tasks in minutes instead of hours. When creating an environment with IsaacGymEnvs via isaacgymenvs.make("Ant"), it creates a vectorized environment which produces GPU tensors as observations and take GPU tensors as actions to execute.
Info
Note that Isaac Gym is the underlying core physics engine, and IssacGymEnvs is a collection of environments built on Isaac Gym.
Info
ppo_continuous_action_isaacgym.py works with most environments in IsaacGymEnvs but it does not work with the following environments yet:
- AnymalTerrain
- FrankaCabinet
- ShadowHandOpenAI_FF
- ShadowHandOpenAI_LSTM
- Trifinger
- Ingenuity Quadcopter
🔥 we need contributors to work on supporting and tuning our PPO implementation in these envs. If you are interested, please read our contribution guide and reach out!
Usage
The installation of isaacgym requires a bit of work since it's not a standard Python package.
Please go to https://developer.nvidia.com/isaac-gym to download and install the latest version of Issac Gym which should look like IsaacGym_Preview_4_Package.tar.gz. Put this IsaacGym_Preview_4_Package.tar.gz into the ~/Downloads/ folder. Make sure your python version is either 3.7, or 3.8 (3.9 not supported yet).
# extract and move the content in `python` folder in the IsaacGym_Preview_4_Package.tar.gz
# into the `cleanrl/ppo_continuous_action_isaacgym/isaacgym/` folder
cp ~/Downloads/IsaacGym_Preview_4_Package.tar.gz IsaacGym_Preview_4_Package.tar.gz
stat IsaacGym_Preview_4_Package.tar.gz
mkdir temp_isaacgym
tar -xf IsaacGym_Preview_4_Package.tar.gz -C temp_isaacgym
mv temp_isaacgym/isaacgym/python/* cleanrl/ppo_continuous_action_isaacgym/isaacgym
rm -rf temp_isaacgym
# if your global python version is not either 3.7 nor 3.8, you need to tell poetry specifically to use a 3.7 or 3.8 python
# e.g., `poetry env use /home/costa/.pyenv/versions/3.7.8/bin/python`
poetry install --with isaacgym
# if you are using NVIDIA's 30xx GPU, you need to specifically install cuda 11.3 wheels
# `poetry run pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu113`
poetry run python cleanrl/ppo_continuous_action_isaacgym/ppo_continuous_action_isaacgym.py --help
poetry run python cleanrl/ppo_continuous_action_isaacgym/ppo_continuous_action_isaacgym.py --env-id Ant
Warning
If you encounter the following installation error
Python.h: No such file or directory
#include <Python.h>
or
libpython3.8.so.1.0: cannot open shared object file: No such file or directory
It usually means your python distribution does not include the shared library files. If you are ubuntu, you can install the following packages:
sudo apt-get install libpython3.8-dev # or sudo apt-get install libpython3.7-dev
If you are using pyenv, you may try the following:
env PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install 3.7.8
Explanation of the logged metrics
See related docs for ppo.py.
Additionally, charts/consecutive_successes means the number of consecutive episodes that the agent has successfully manipulating the rubix cube to the desired state.
Implementation details
ppo_continuous_action_isaacgym.py is based on ppo_continuous_action.py (see related docs), with a few modifications:
- Different set of hyperparameters:
ppo_continuous_action_isaacgym.pyuses hyperparameters primarily derived from rl-games' configuration (see example). The basic spirit is to run moretotal_timesteps, with largernum_envsand smallernum_steps.
| arguments | ppo_continuous_action.py |
ppo_continuous_action_isaacgym.py |
ppo_continuous_action_isaacgym.py (for ShadowHand and AllegroHand) |
|---|---|---|---|
| --total-timesteps | 1000000 | 30000000 | 600000000 |
| --learning-rate | 3e-4 | 0.0026 | 0.0026 |
| --num-envs | 1 | 4096 | 8192 |
| --num-steps | 2048 | 16 | 8 |
| --anneal-lr | True | False | False |
| --num-minibatches | 32 | 2 | 4 |
| --update-epochs | 10 | 4 | 5 |
| --clip-vloss | True | False | False |
| --vf-coef | 0.5 | 2 | 2 |
| --max-grad-norm | 0.5 | 1 | 1 |
| --reward-scaler | N/A | 1 | 0.01 |
- Slightly larger NN:
ppo_continuous_action.pyuses the following NN:whileself.critic = nn.Sequential( layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)), nn.Tanh(), layer_init(nn.Linear(64, 64)), nn.Tanh(), layer_init(nn.Linear(64, 1), std=1.0), ) self.actor_mean = nn.Sequential( layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)), nn.Tanh(), layer_init(nn.Linear(64, 64)), nn.Tanh(), layer_init(nn.Linear(64, np.prod(envs.single_action_space.shape)), std=0.01), )ppo_continuous_action_isaacgym.pyuses the following NN:self.critic = nn.Sequential( layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 256)), nn.Tanh(), layer_init(nn.Linear(256, 256)), nn.Tanh(), layer_init(nn.Linear(256, 1), std=1.0), ) self.actor_mean = nn.Sequential( layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 256)), nn.Tanh(), layer_init(nn.Linear(256, 256)), nn.Tanh(), layer_init(nn.Linear(256, np.prod(envs.single_action_space.shape)), std=0.01), ) - No normalization and clipping:
ppo_continuous_action_isaacgym.pydoes not do observation and reward normalization and clipping for simplicity. It does however optionally offer an option to scale the rewards via--reward-scaler x, which multiplies all the rewards obtained byxas an example. - Remove all CPU-related code:
ppo_continuous_action_isaacgym.pyneeds to remove all CPU-related code (e.g.action.cpu().numpy()). This is because almost everything in IsaacGymEnvs happens in GPU. To do this, the major modifications include the following: - Create a custom
RecordEpisodeStatisticsTorchwrapper that records statstics using GPU tensors instead ofnumpyarrays. - Avoid transferring the tensors to CPU. The related code in
ppo_continuous_action.pylooks likeand the related code innext_obs, reward, done, info = envs.step(action.cpu().numpy()) rewards[step] = torch.tensor(reward).to(device).view(-1) next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(done).to(device)ppo_continuous_action_isaacgym.pylooks likenext_obs, rewards[step], next_done, info = envs.step(action)
Experiment results
To run benchmark experiments, see benchmark/ppo.sh. Specifically, execute the following command:
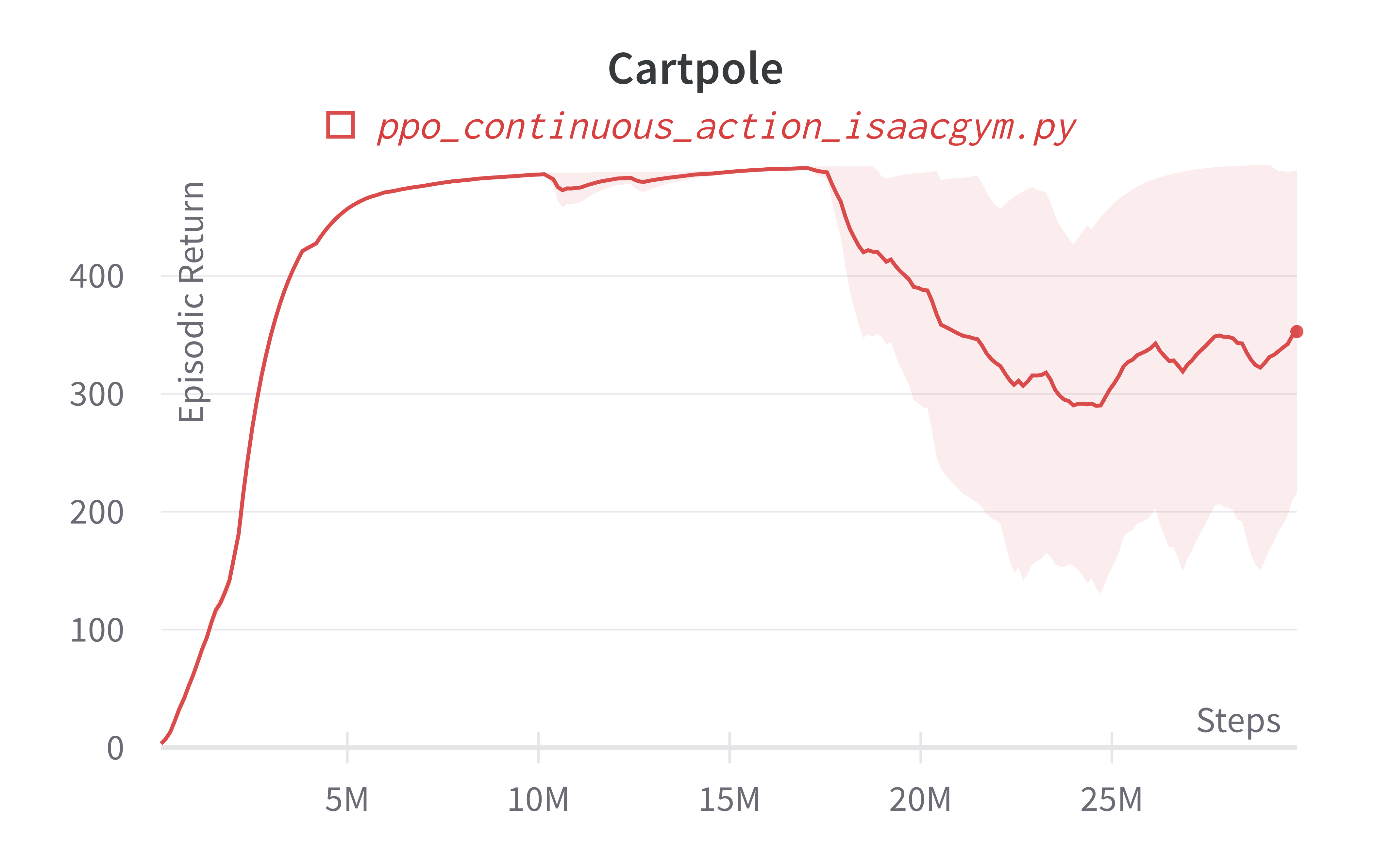
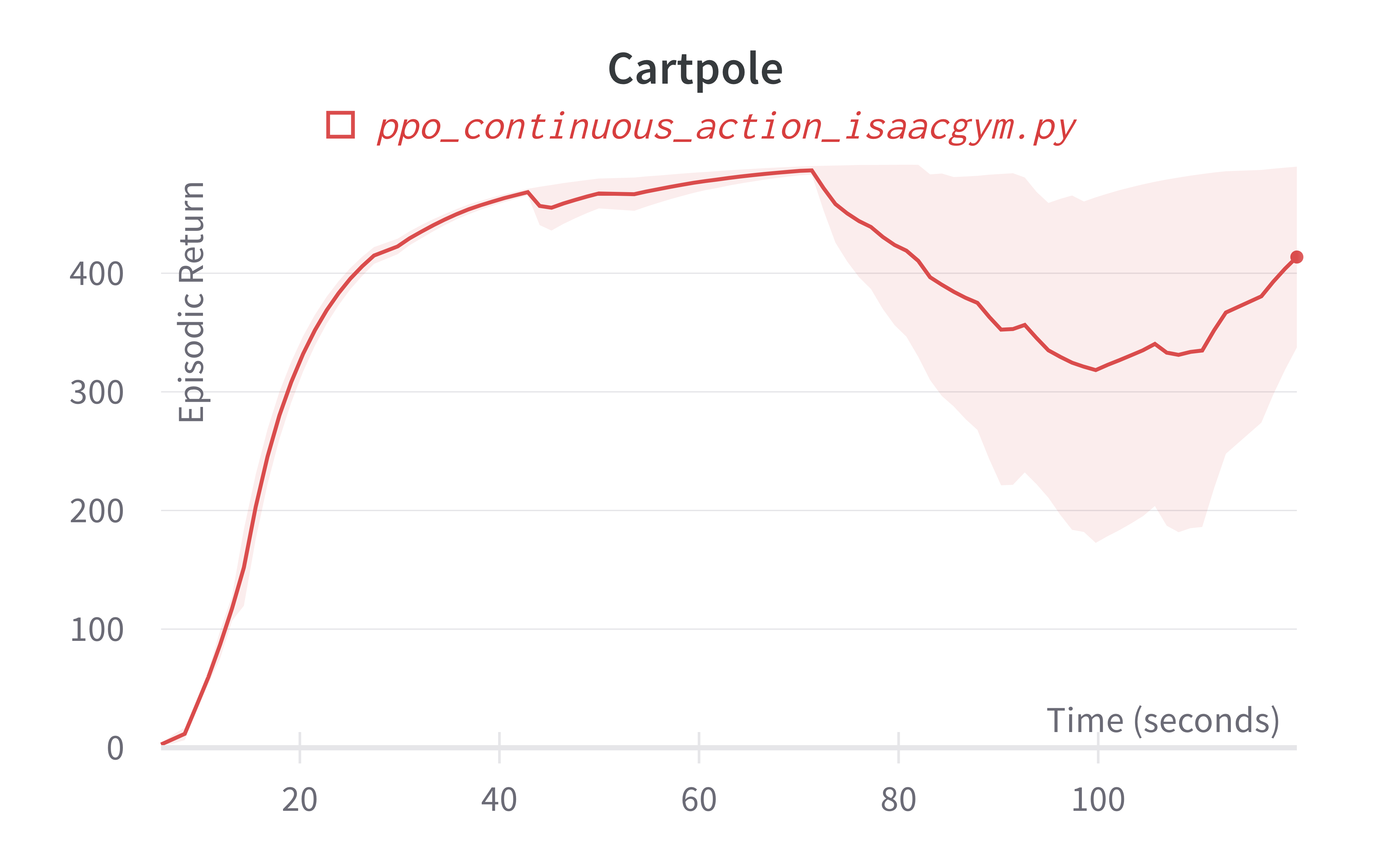
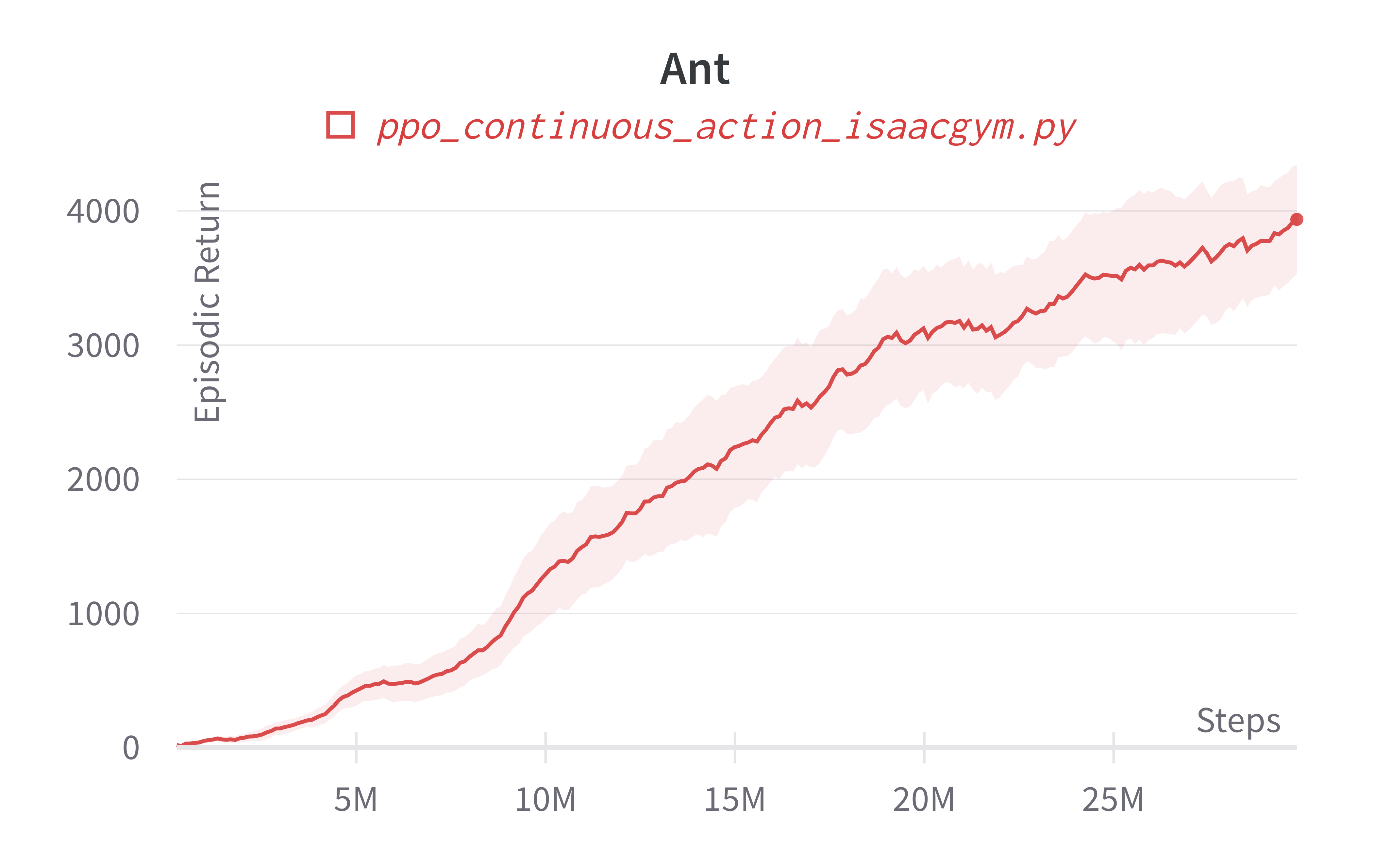
Below are the average episodic returns for ppo_continuous_action_isaacgym.py. To ensure the quality of the implementation, we compared the results against Denys88/rl_games' PPO and present the training time (units being s (seconds), m (minutes)). The hardware used is a NVIDIA RTX A6000 in a 24 core machine.
| Environment (training time) | ppo_continuous_action_isaacgym.py |
Denys88/rl_games |
|---|---|---|
| Cartpole (40s) | 413.66 ± 120.93 | 417.49 (30s) |
| Ant (240s) | 3953.30 ± 667.086 | 5873.05 |
| Humanoid (350s) | 2987.95 ± 257.60 | 6254.73 |
| Anymal (317s) | 29.34 ± 17.80 | 62.76 |
| BallBalance (160s) | 161.92 ± 89.20 | 319.76 |
| AllegroHand (200m) | 762.93 ± 427.92 | 3479.85 |
| ShadowHand (130m) | 427.16 ± 161.79 | 5713.74 |
Learning curves:
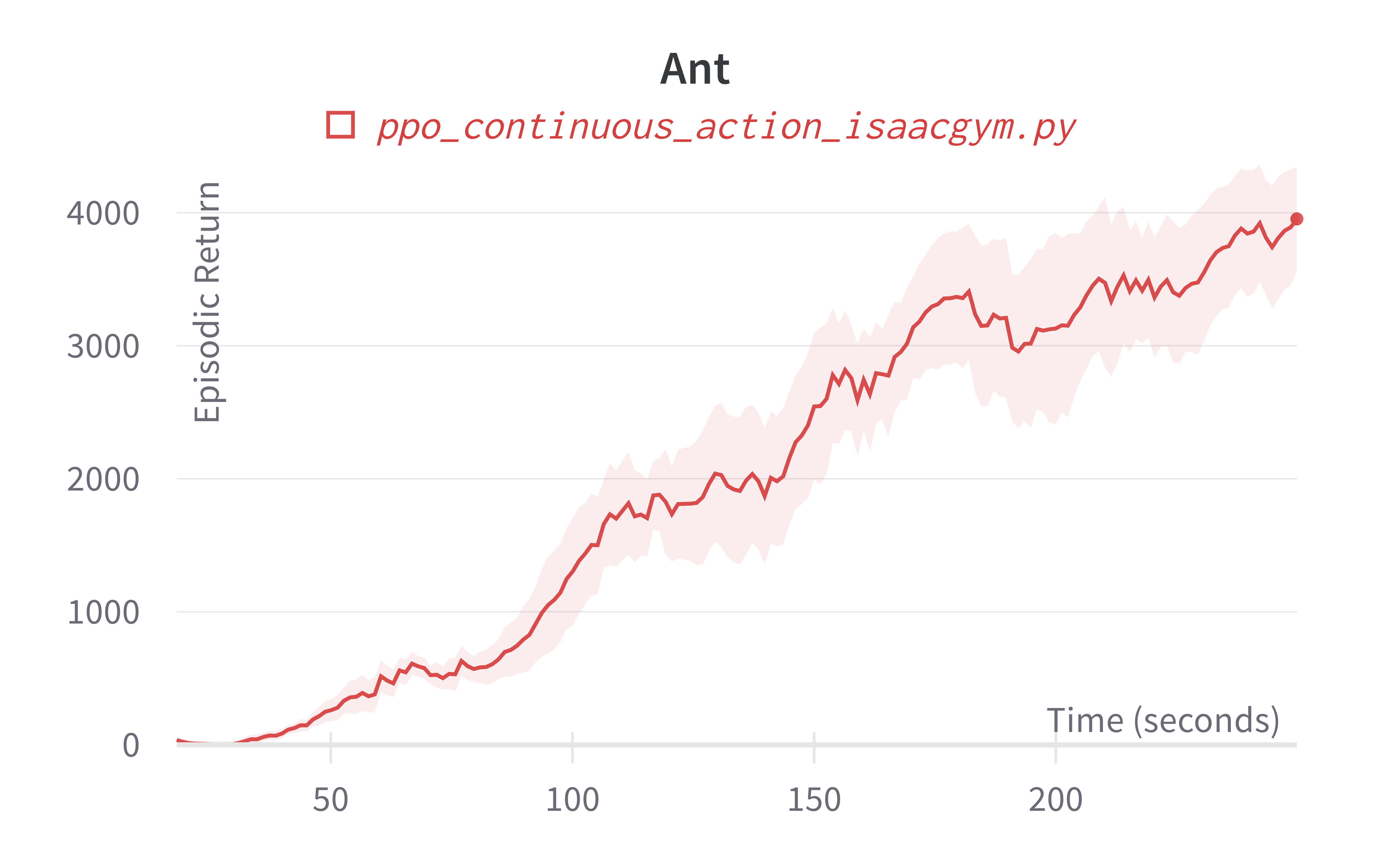
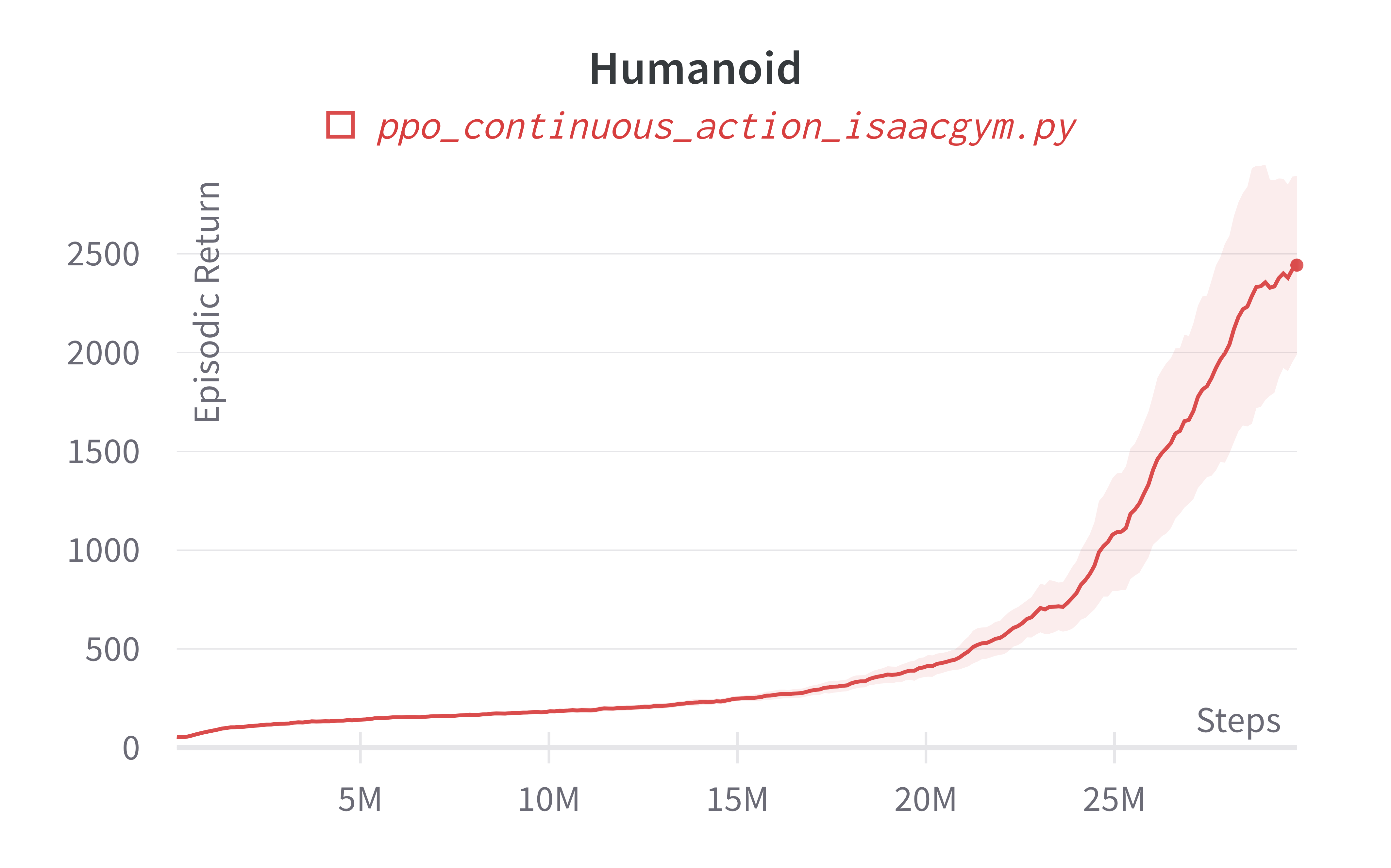
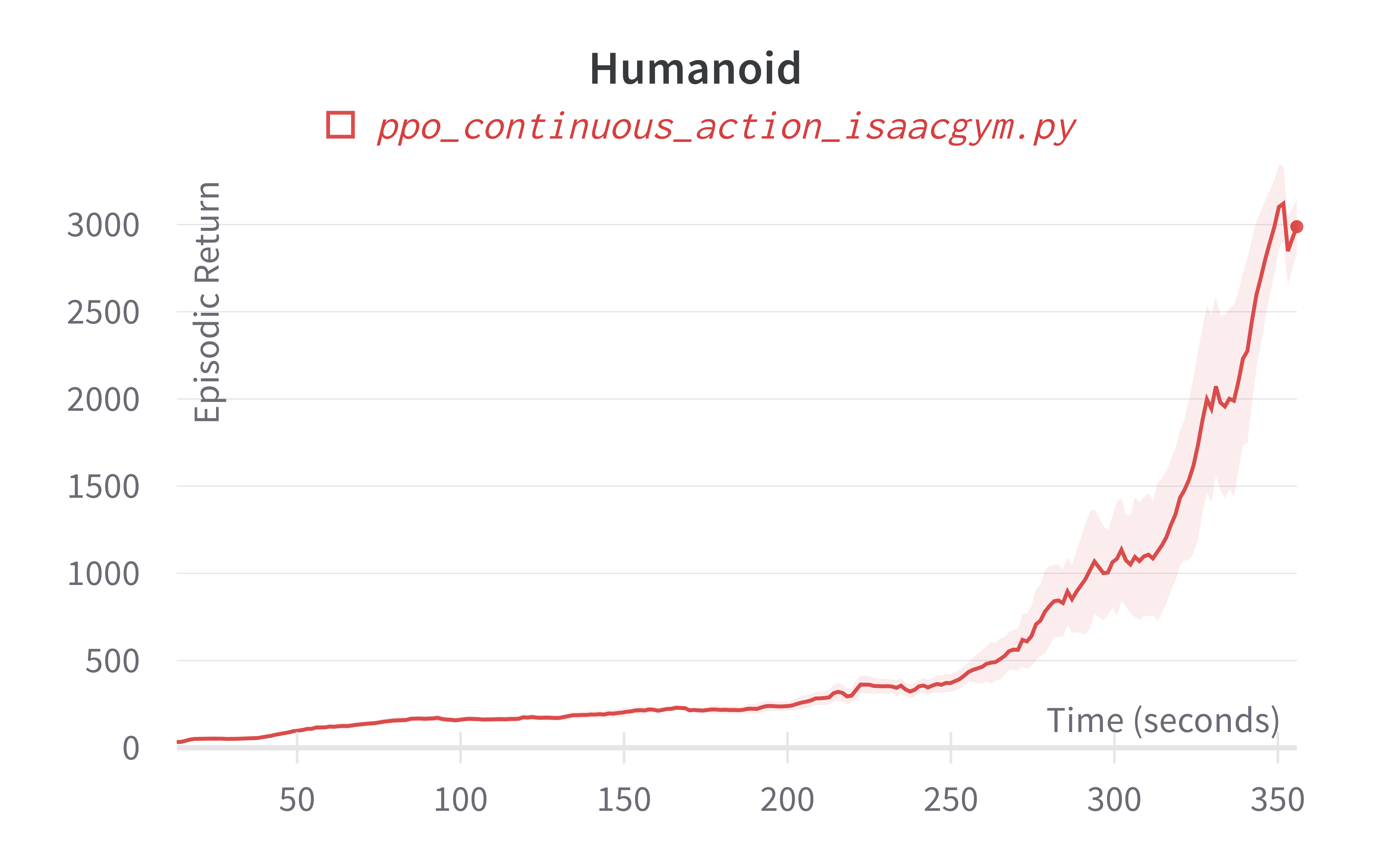
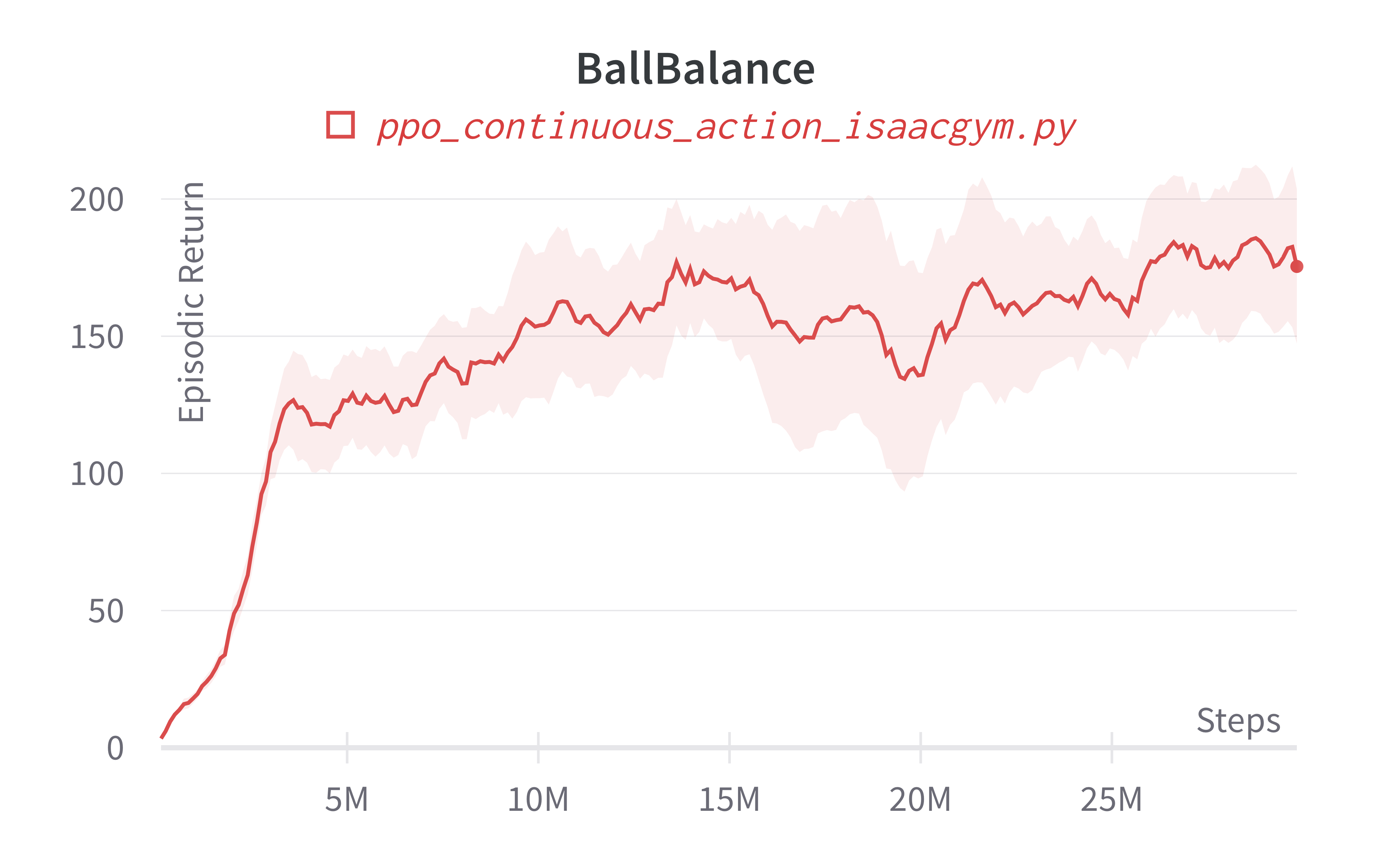
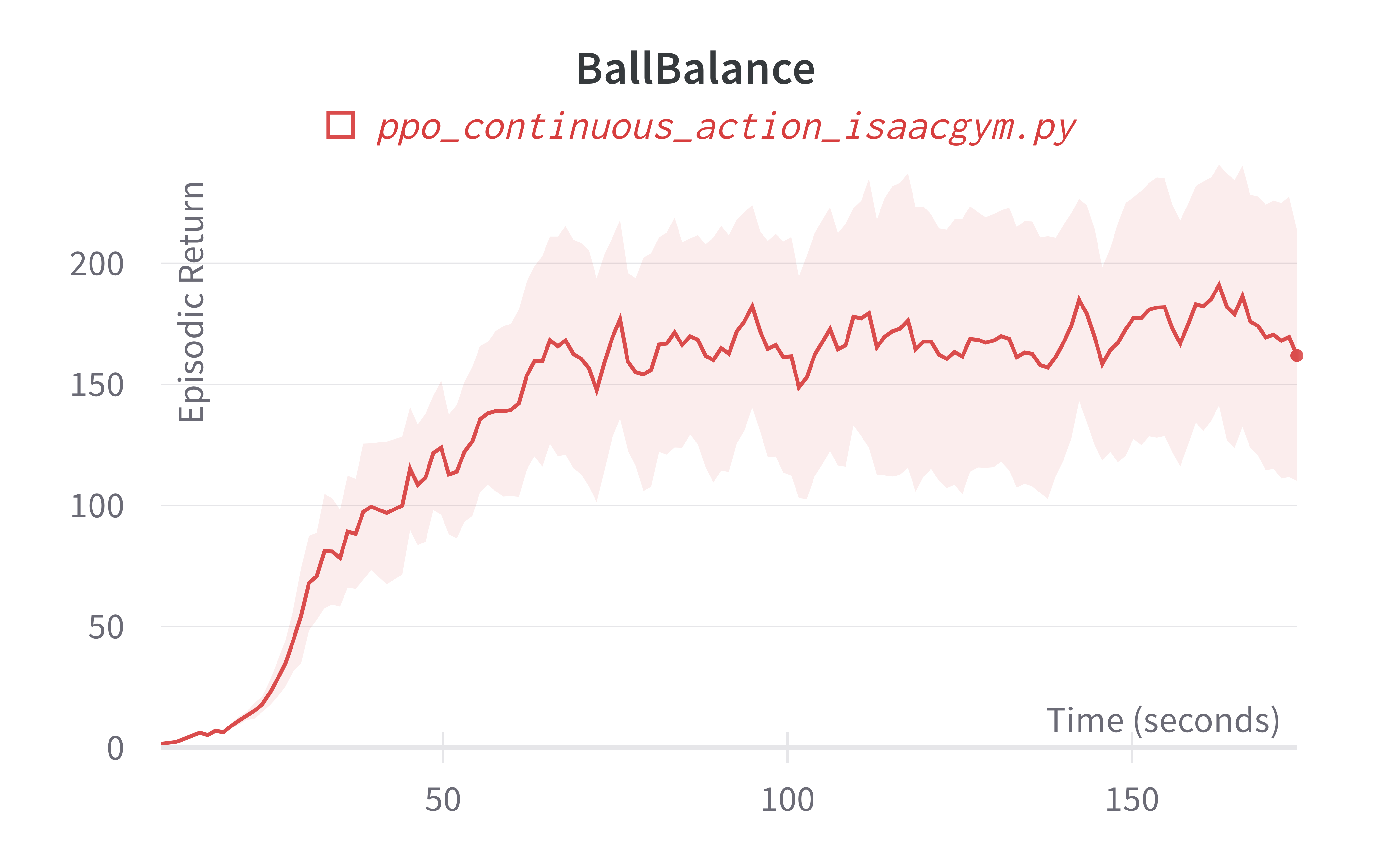
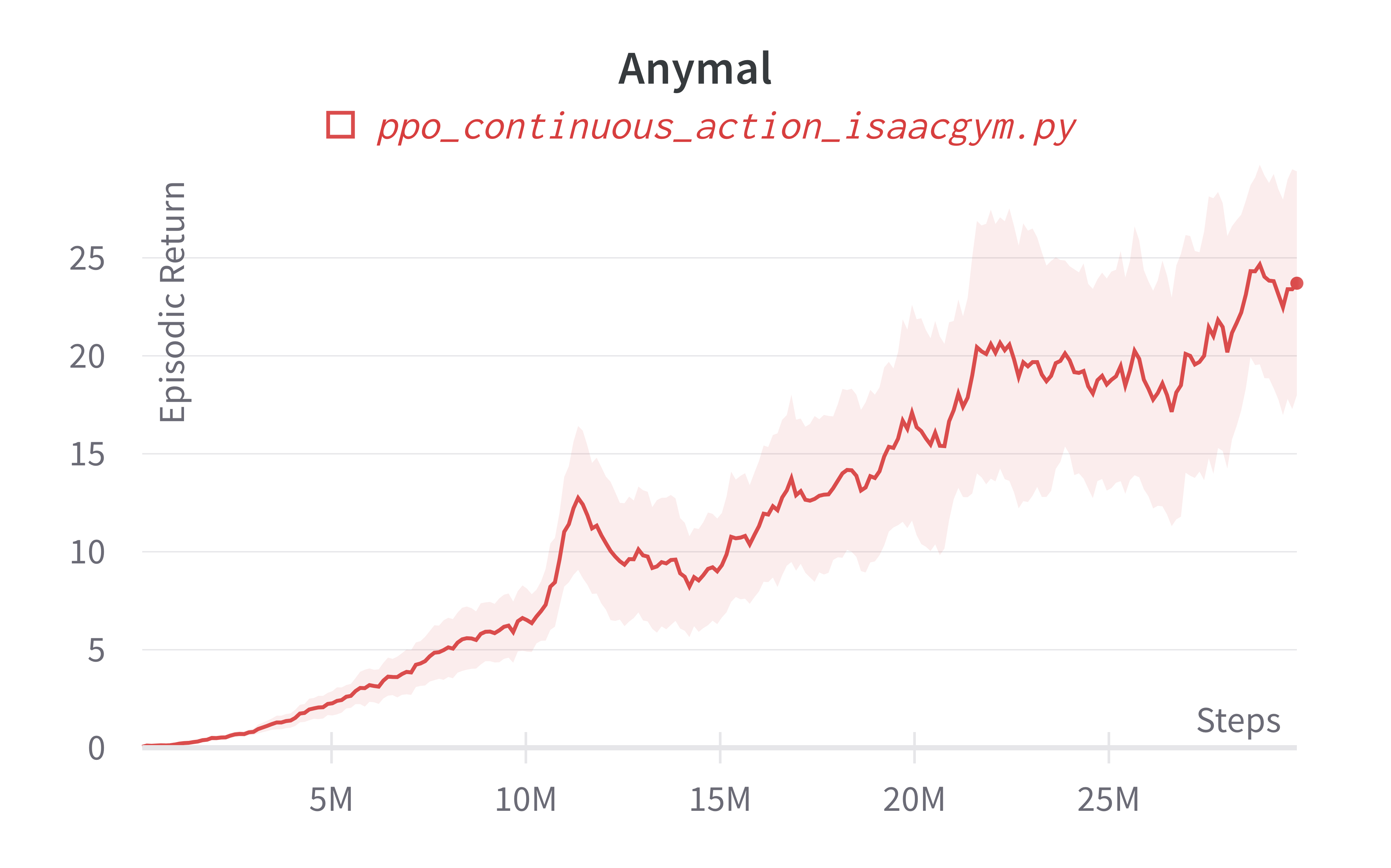
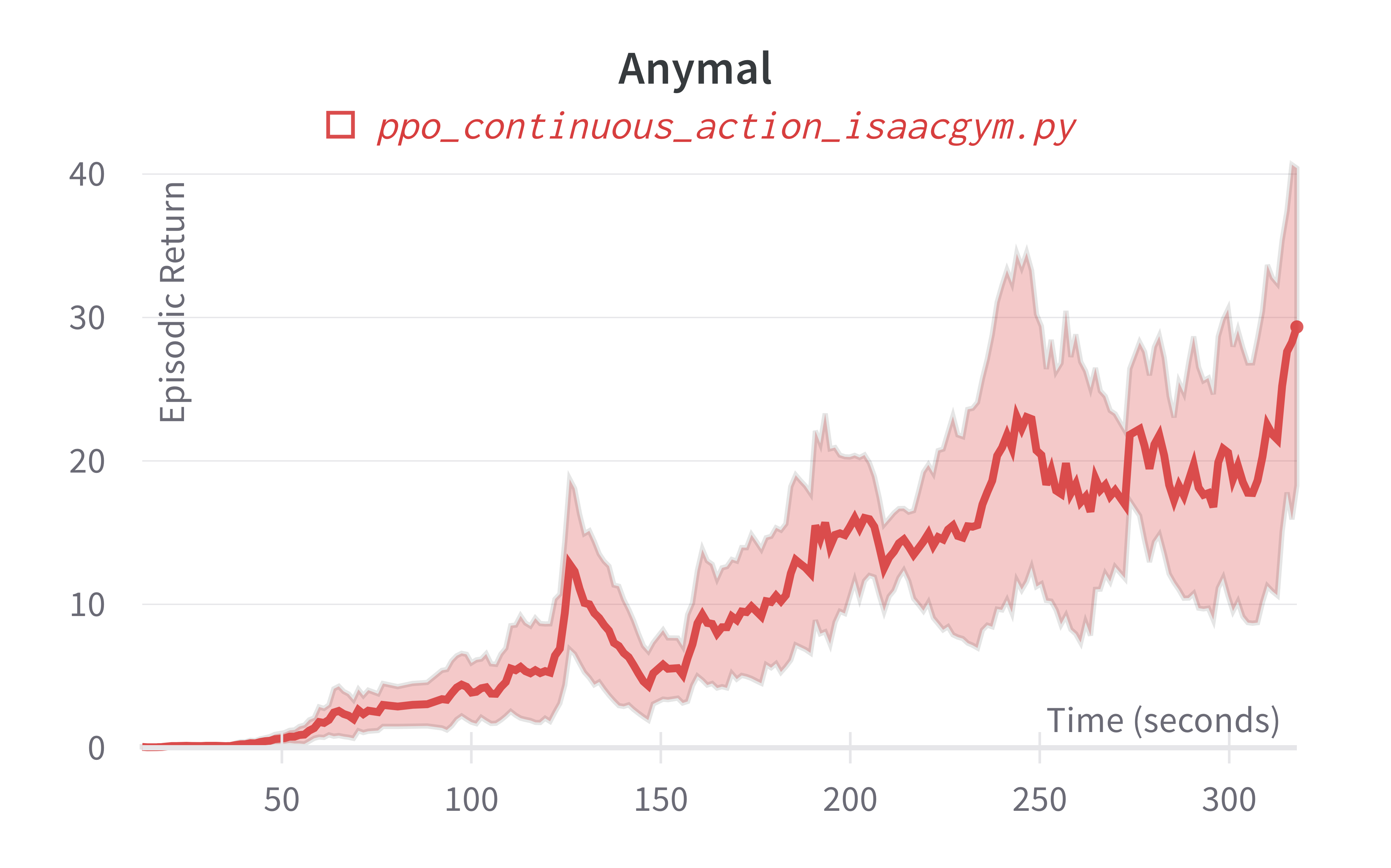
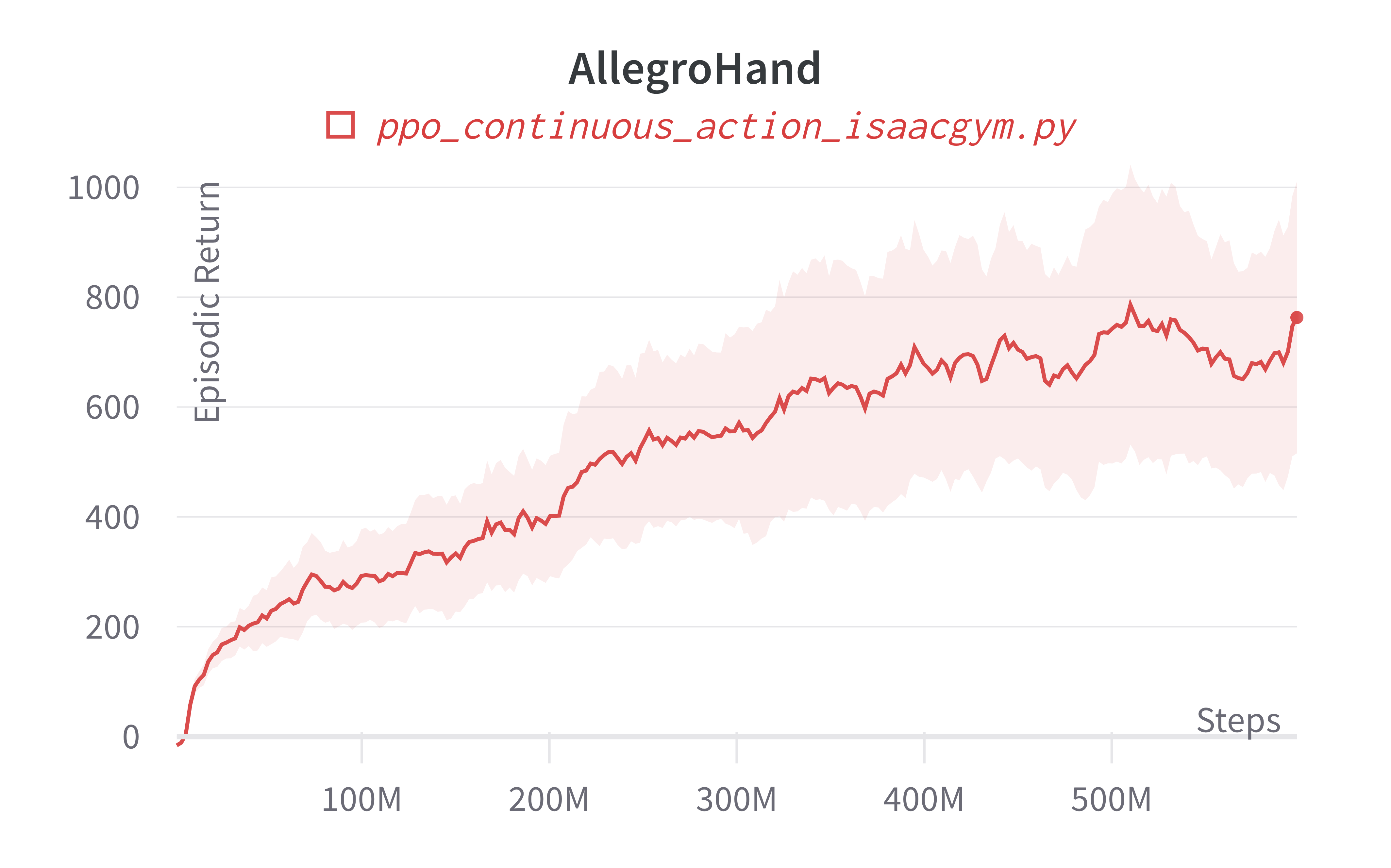
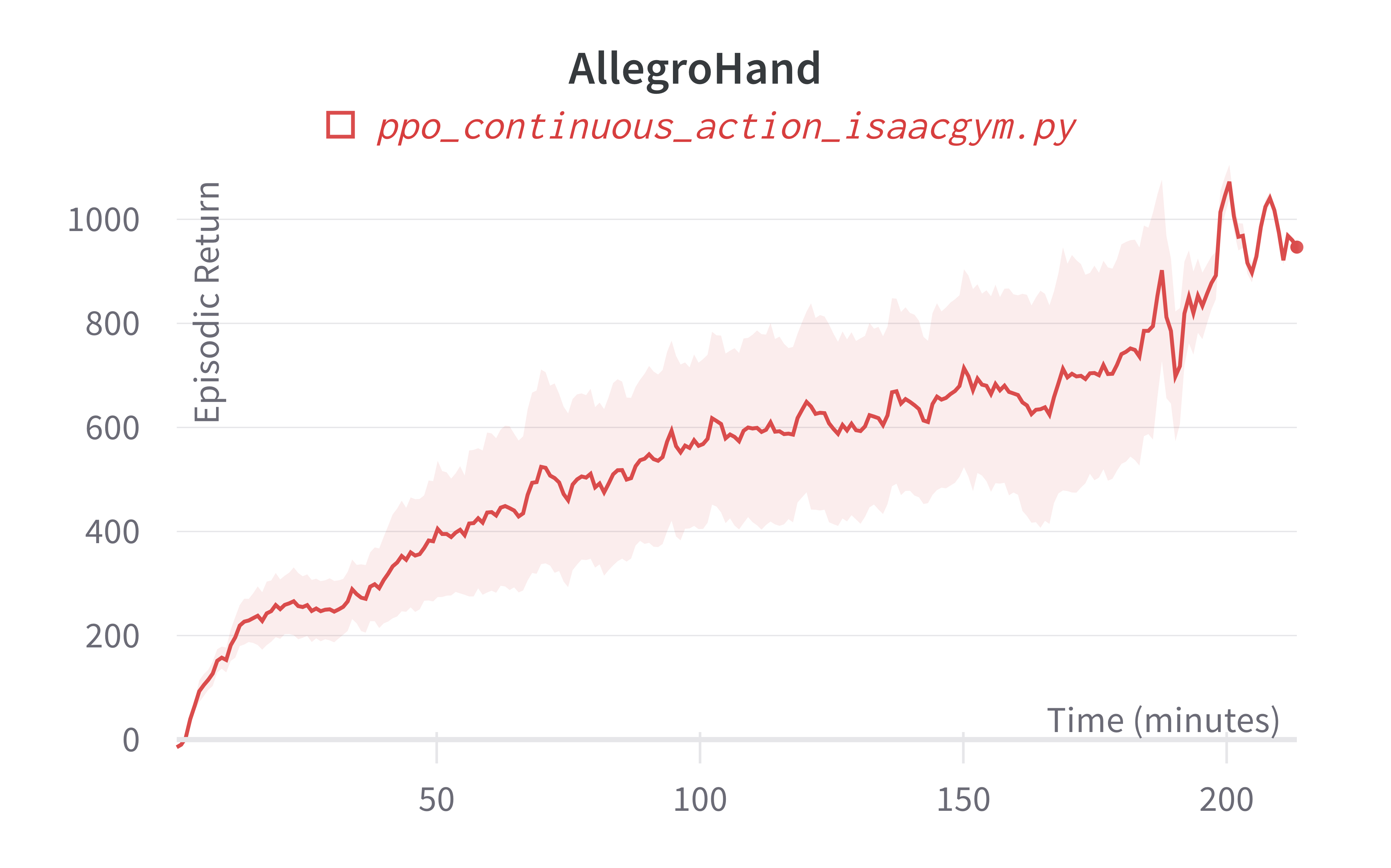
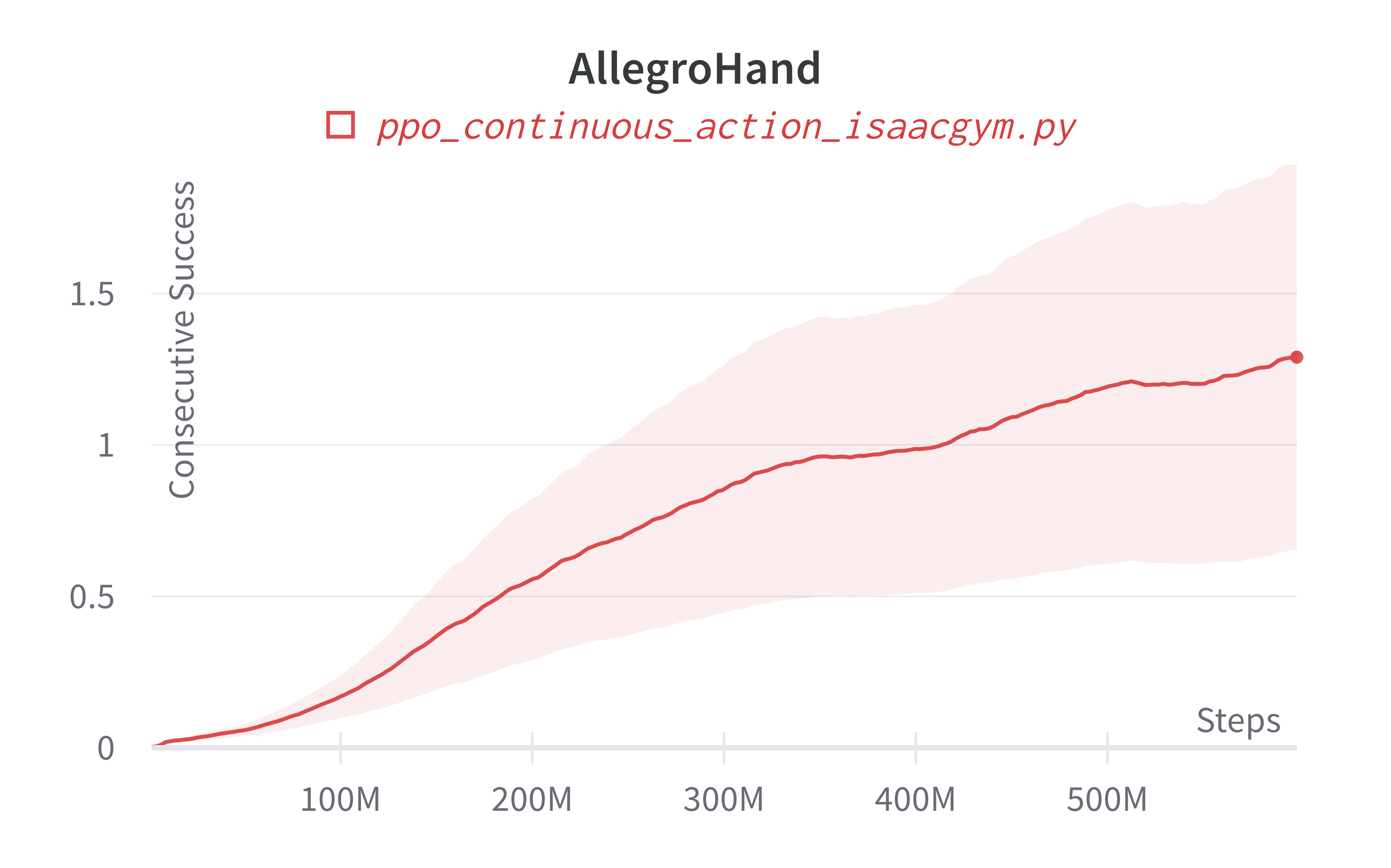
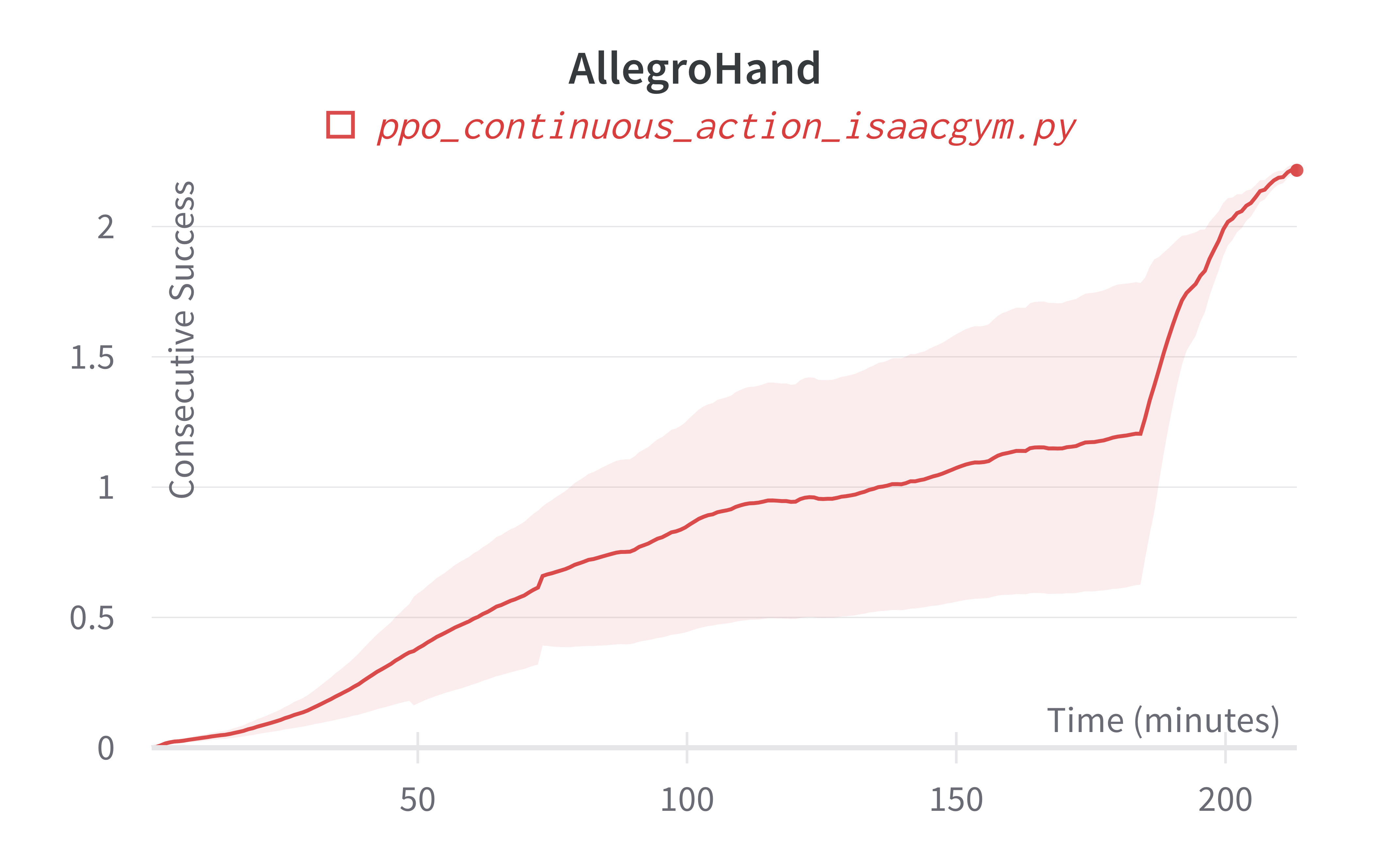
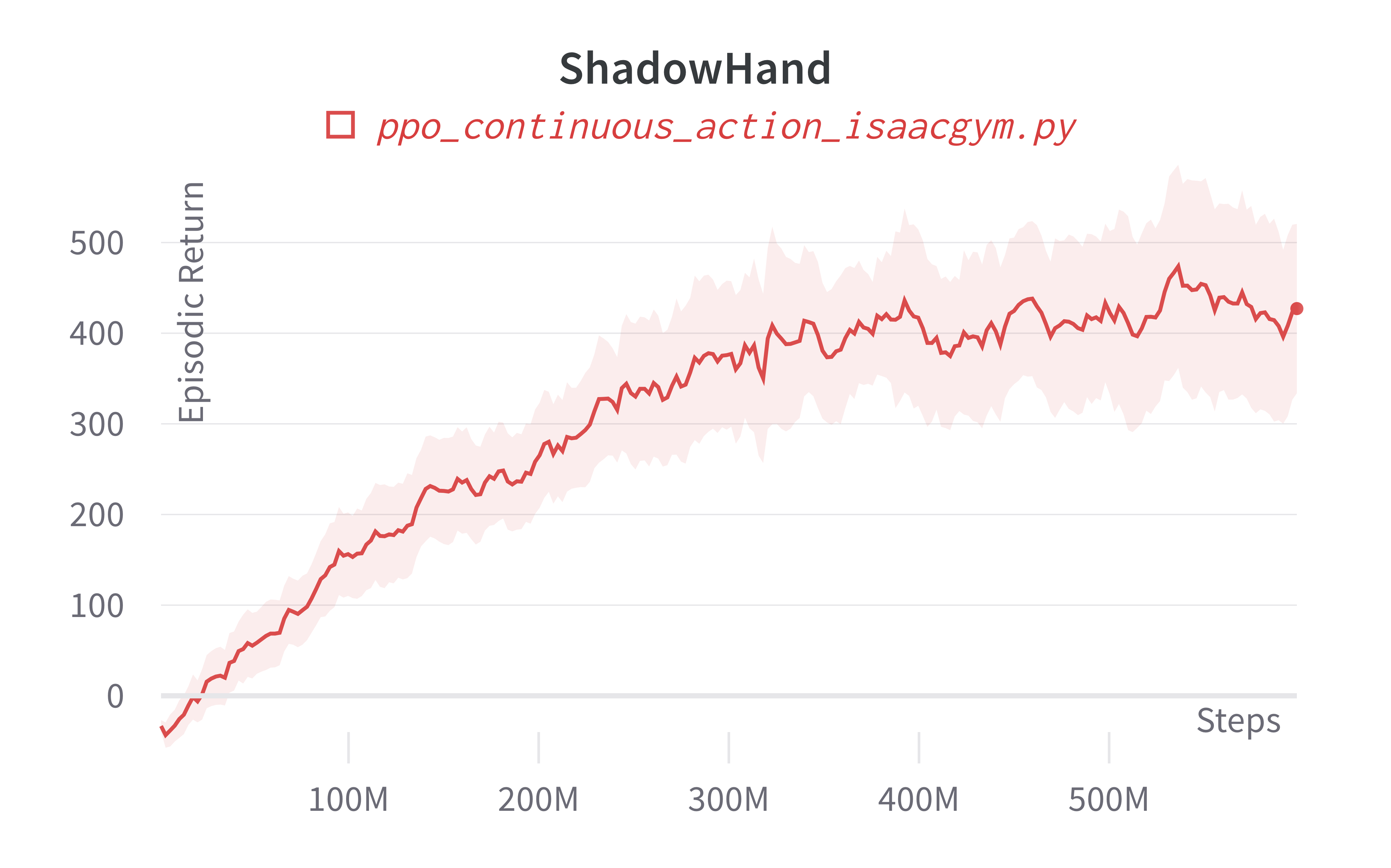
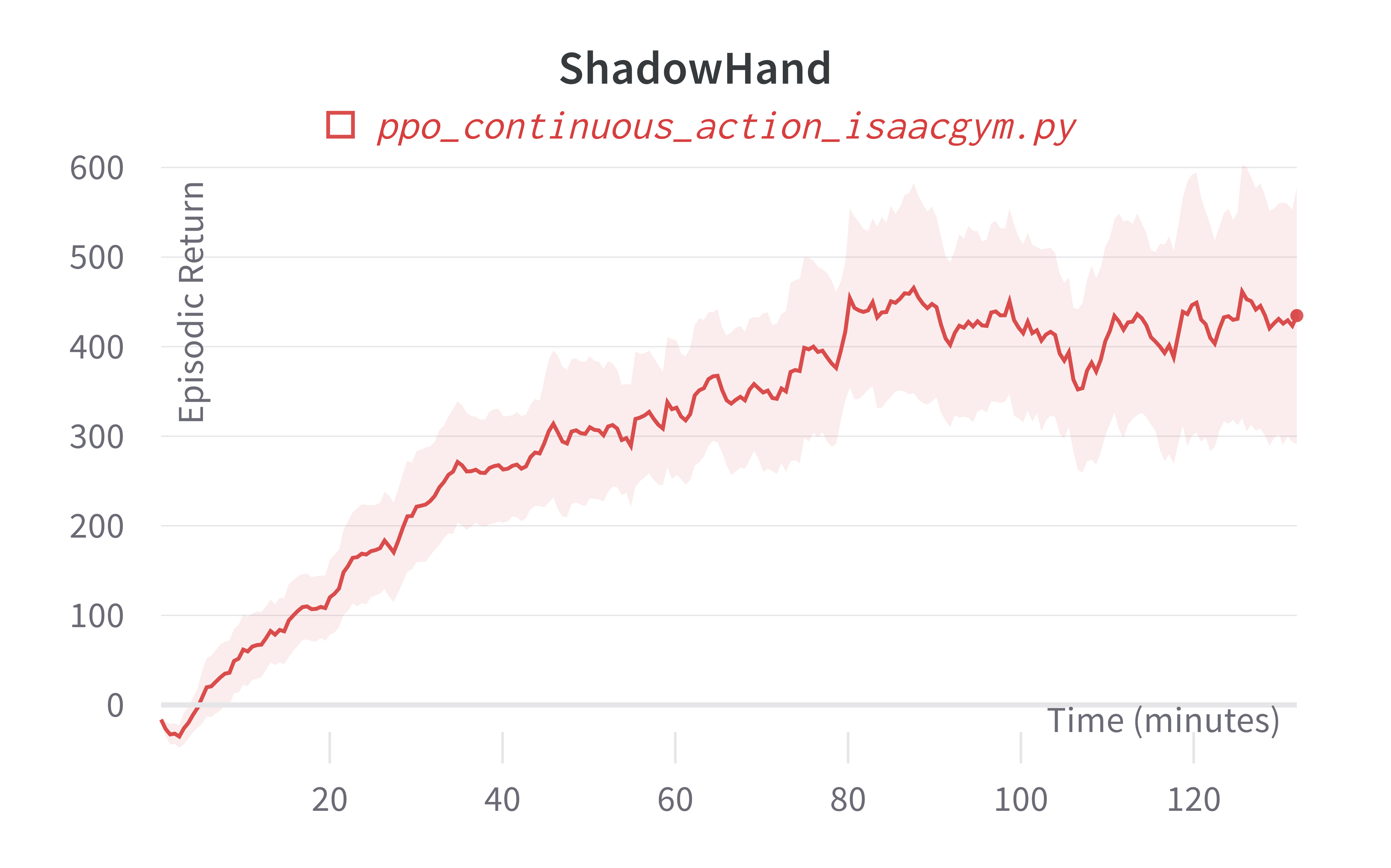
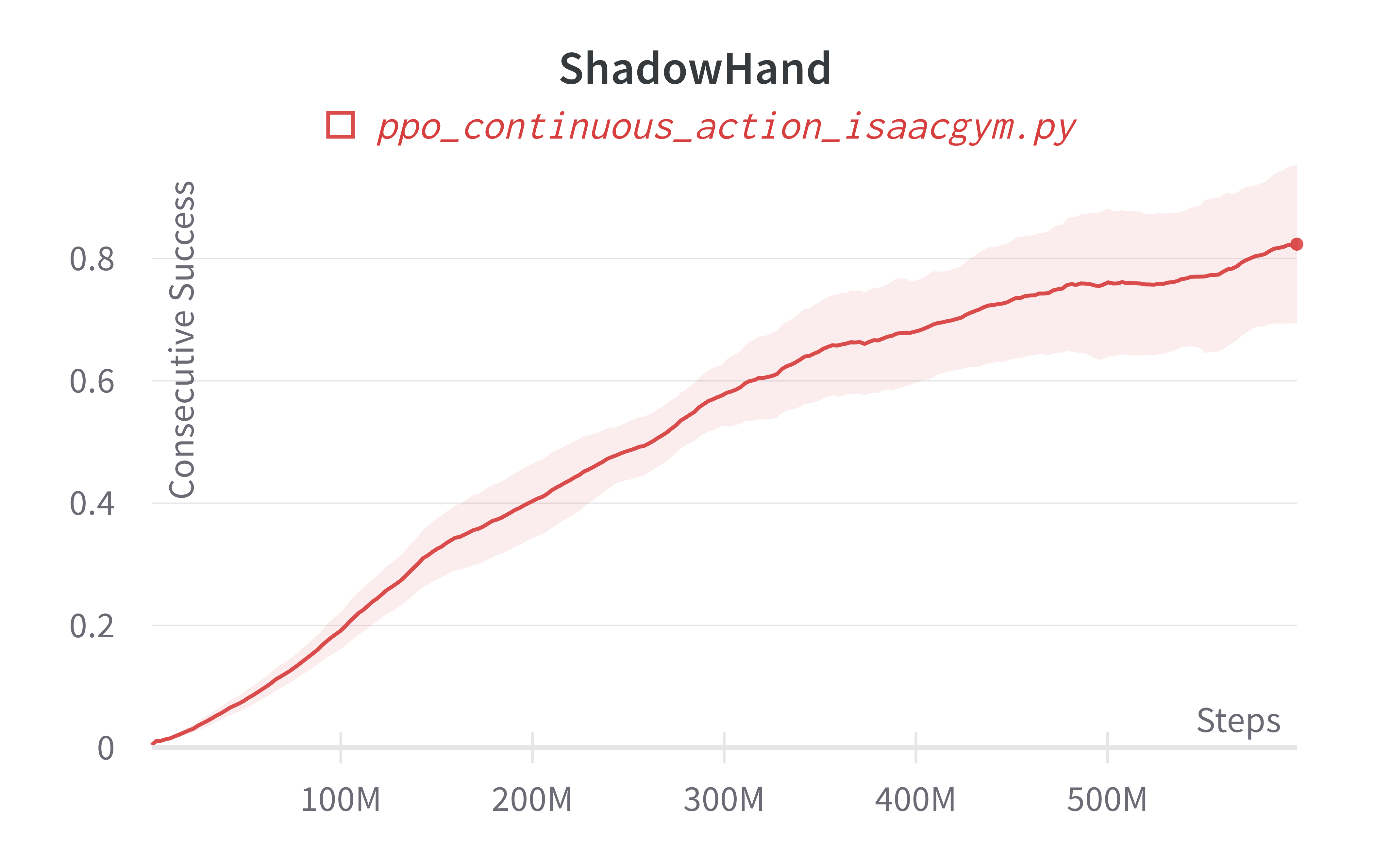
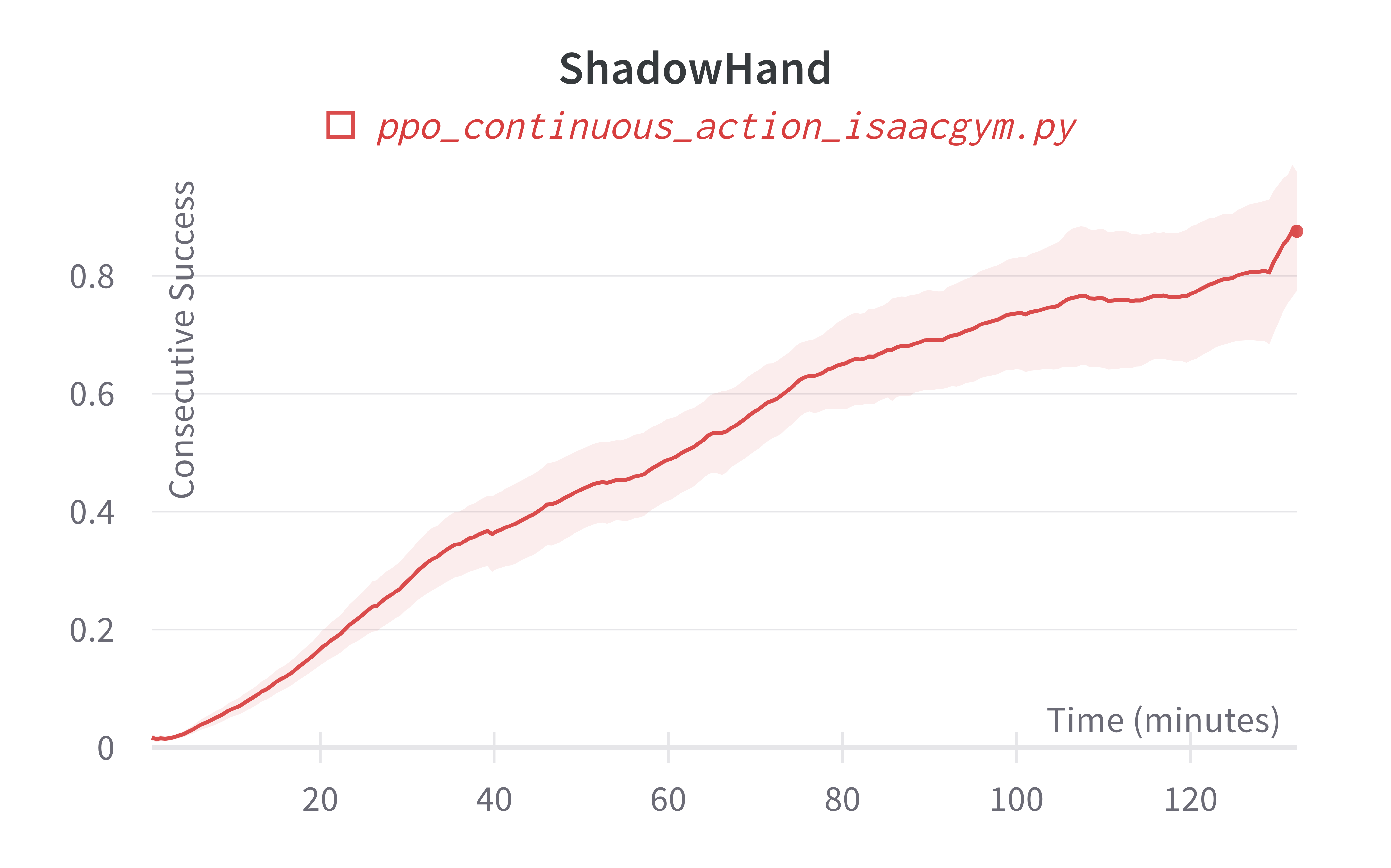
Info
Note ppo_continuous_action_isaacgym.py's performance seems poor compared to Denys88/rl_games' PPO. This is likely due to a few reasons.
- Denys88/rl_games' PPO uses different sets of tuned hyperparameters and neural network architecture configuration for different tasks, whereas
ppo_continuous_action_isaacgym.pyonly uses one neural network architecture and 2 set of hyperparameters (ignoring--total-timesteps). ppo_continuous_action_isaacgym.pydoes not use observation normalization (because in my preliminary testing for some reasons it did not help).
While it should be possible to obtain higher scores with more tuning, the purpose of ppo_continuous_action_isaacgym.py is to hit a balance between simplicity and performance. I think ppo_continuous_action_isaacgym.py has relatively good performance with a concise codebase, which should be easy to modify and extend for practitioners.
Tracked experiments and game play videos:
Old Learning curves w/ Isaac Gym Preview 3 (no longer available in Nvidia's website for download):
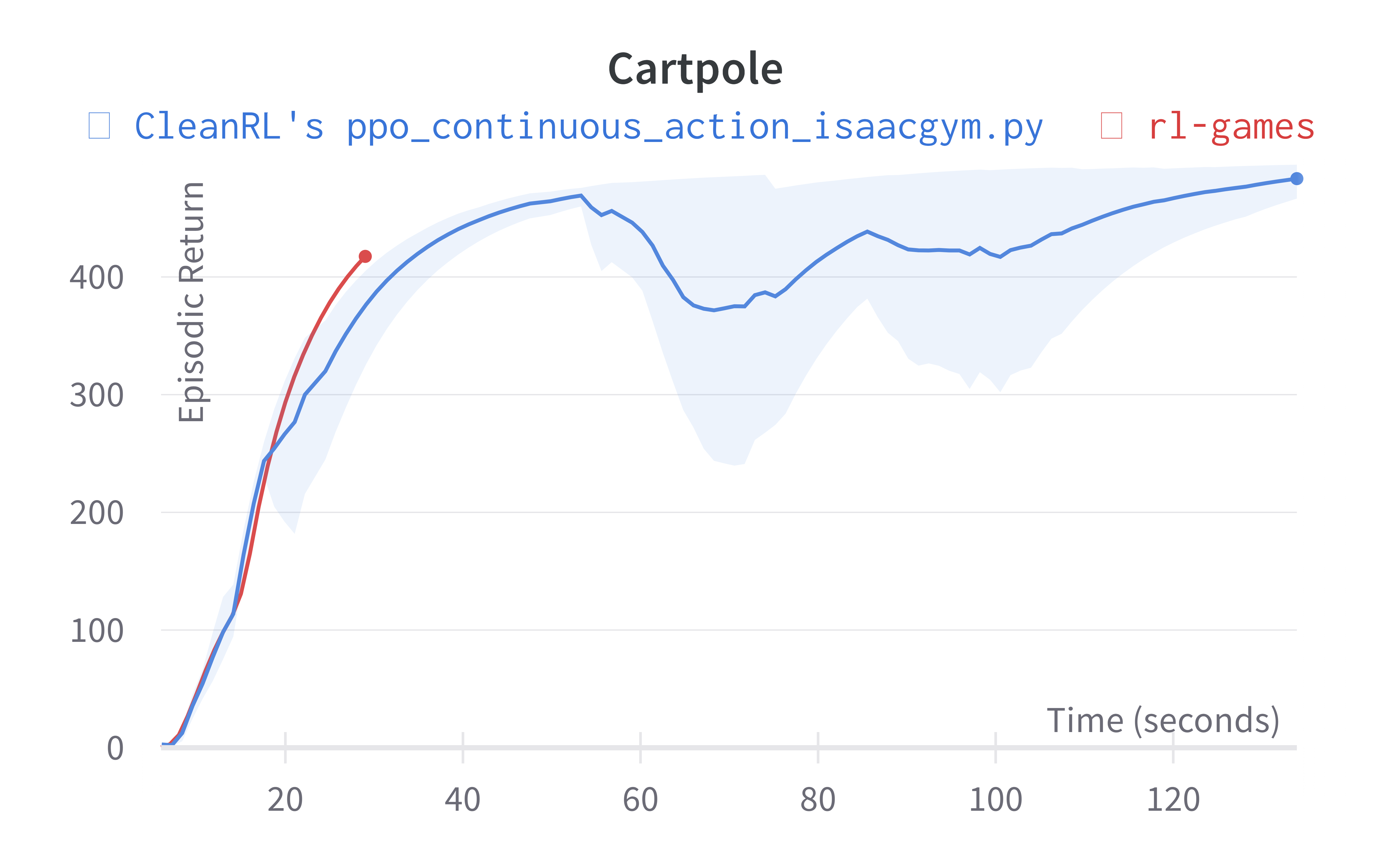
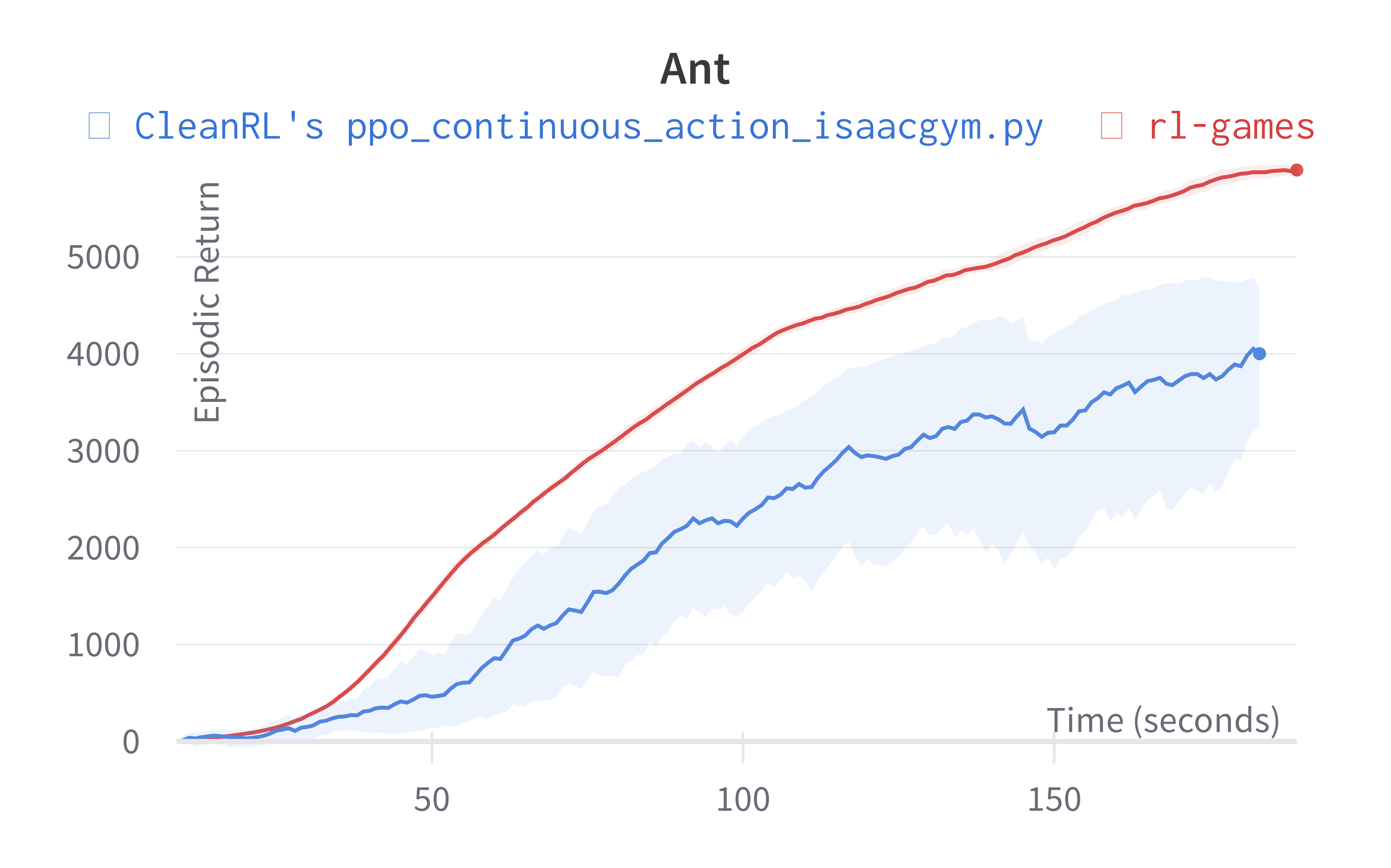
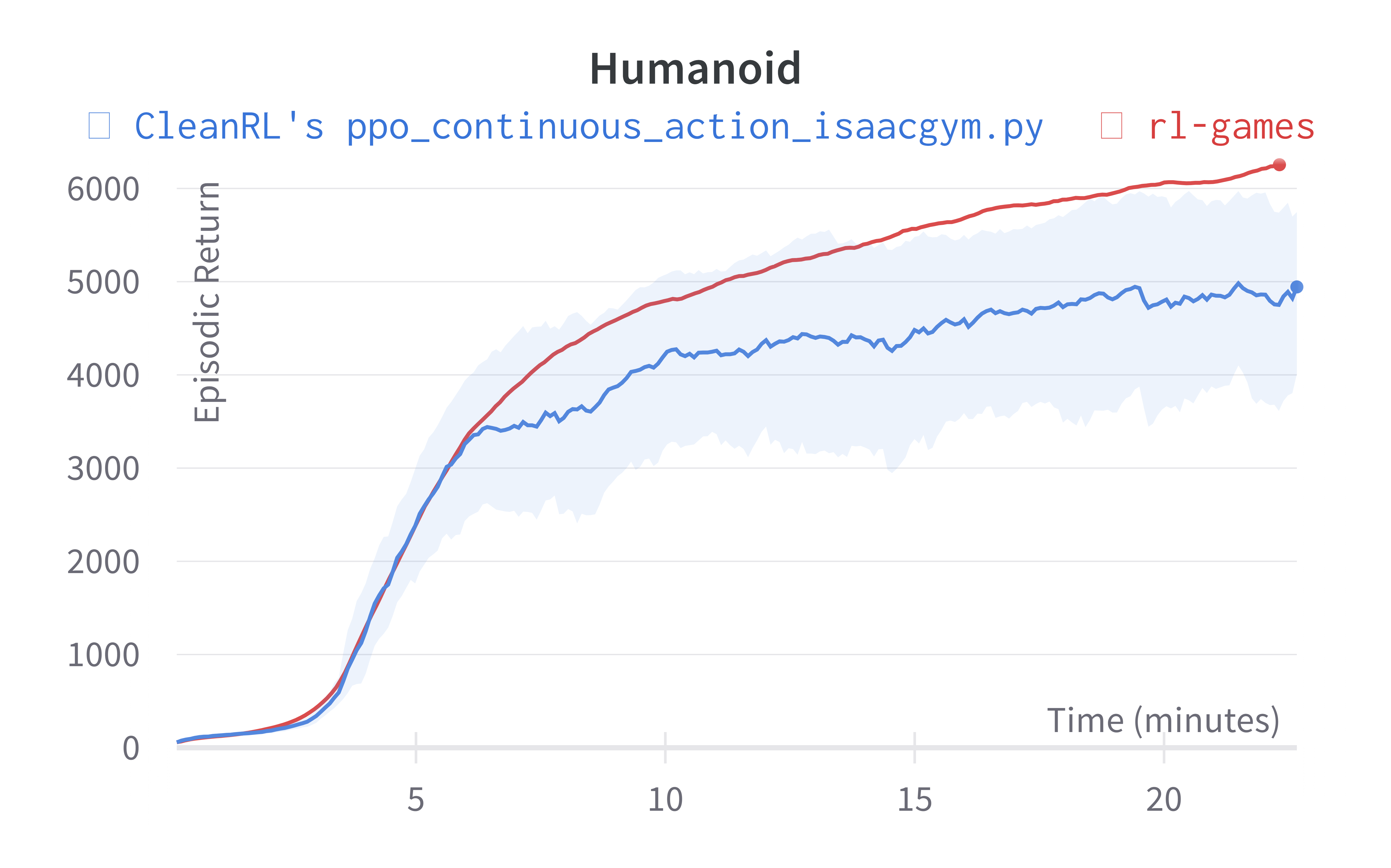
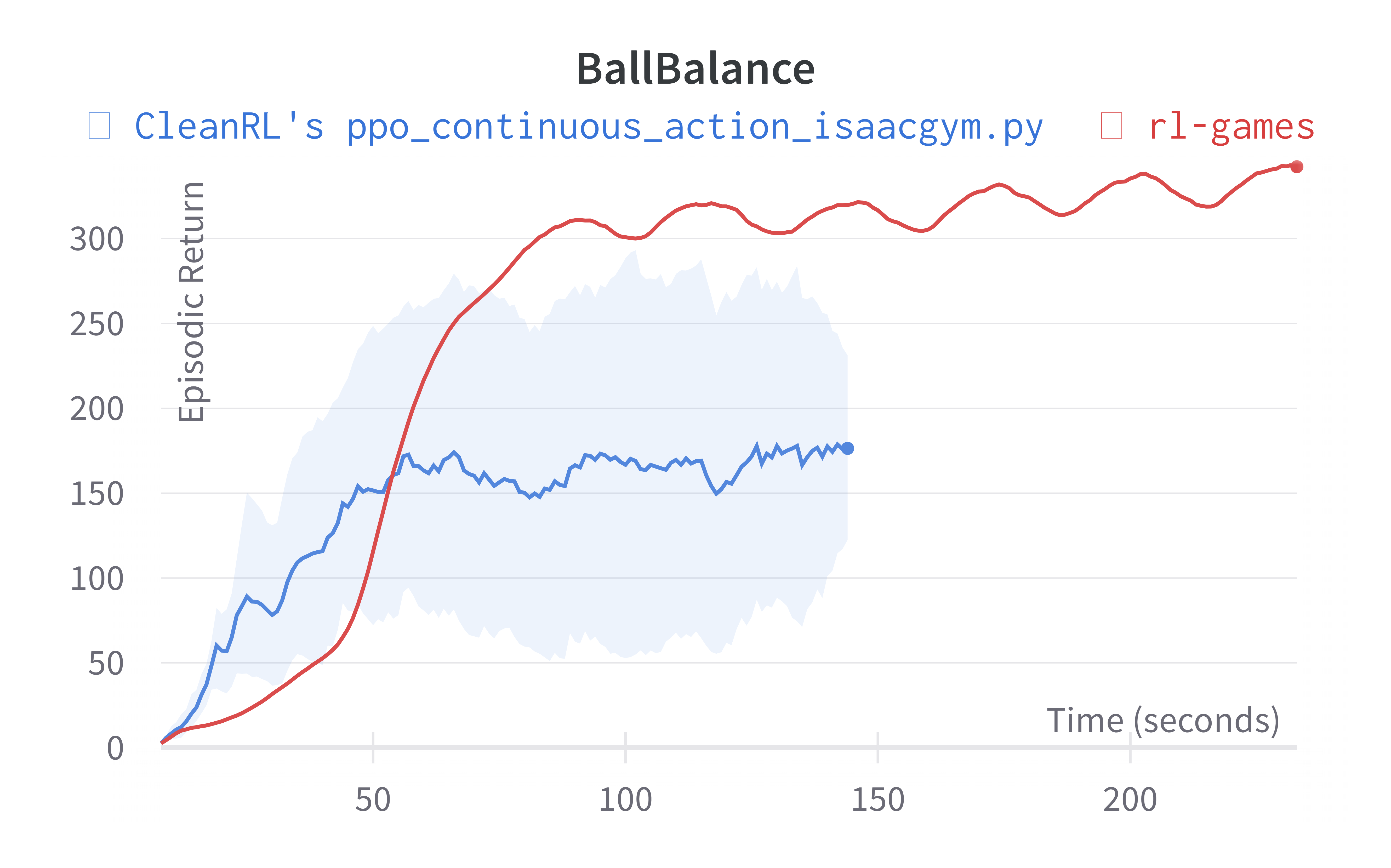
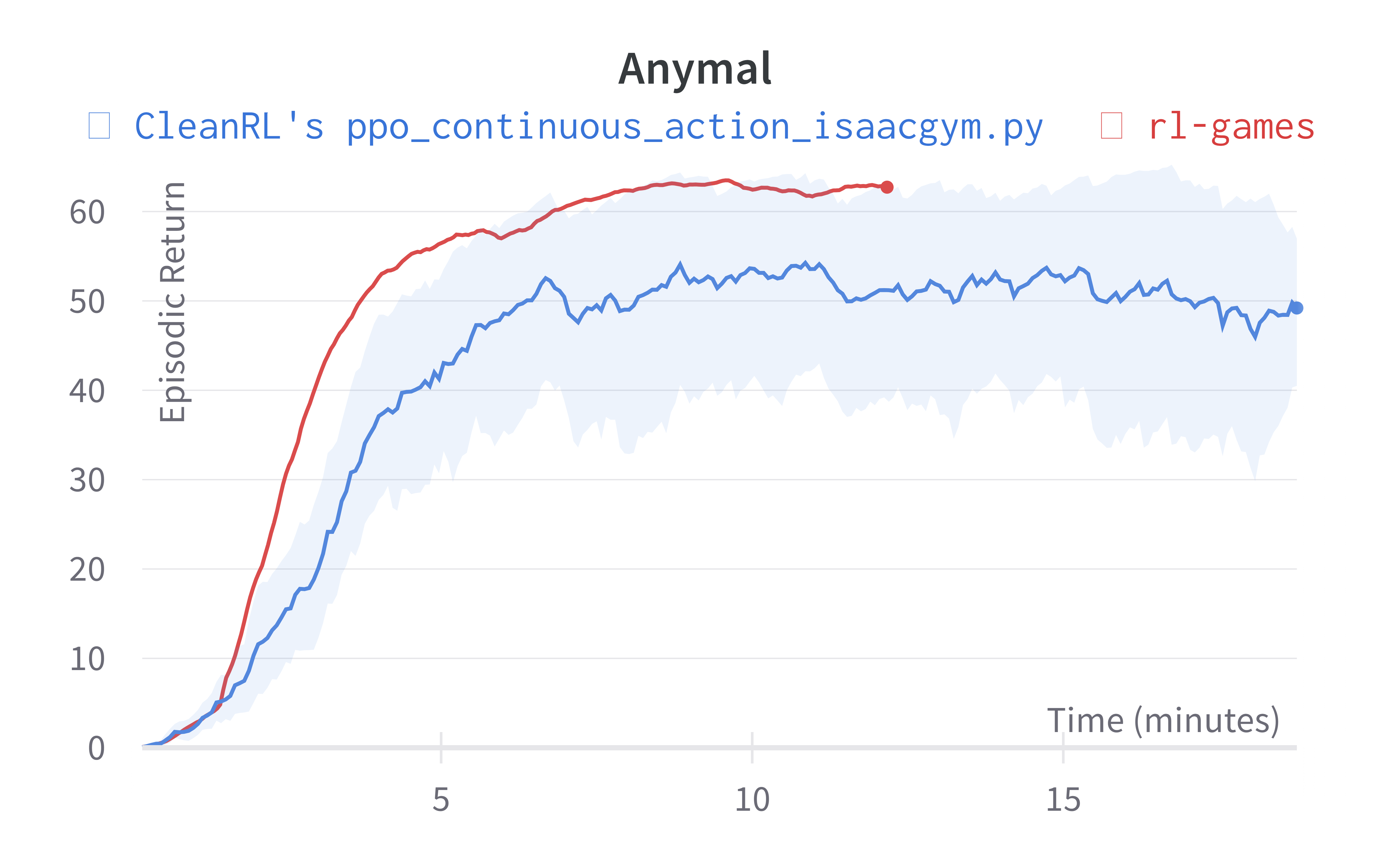
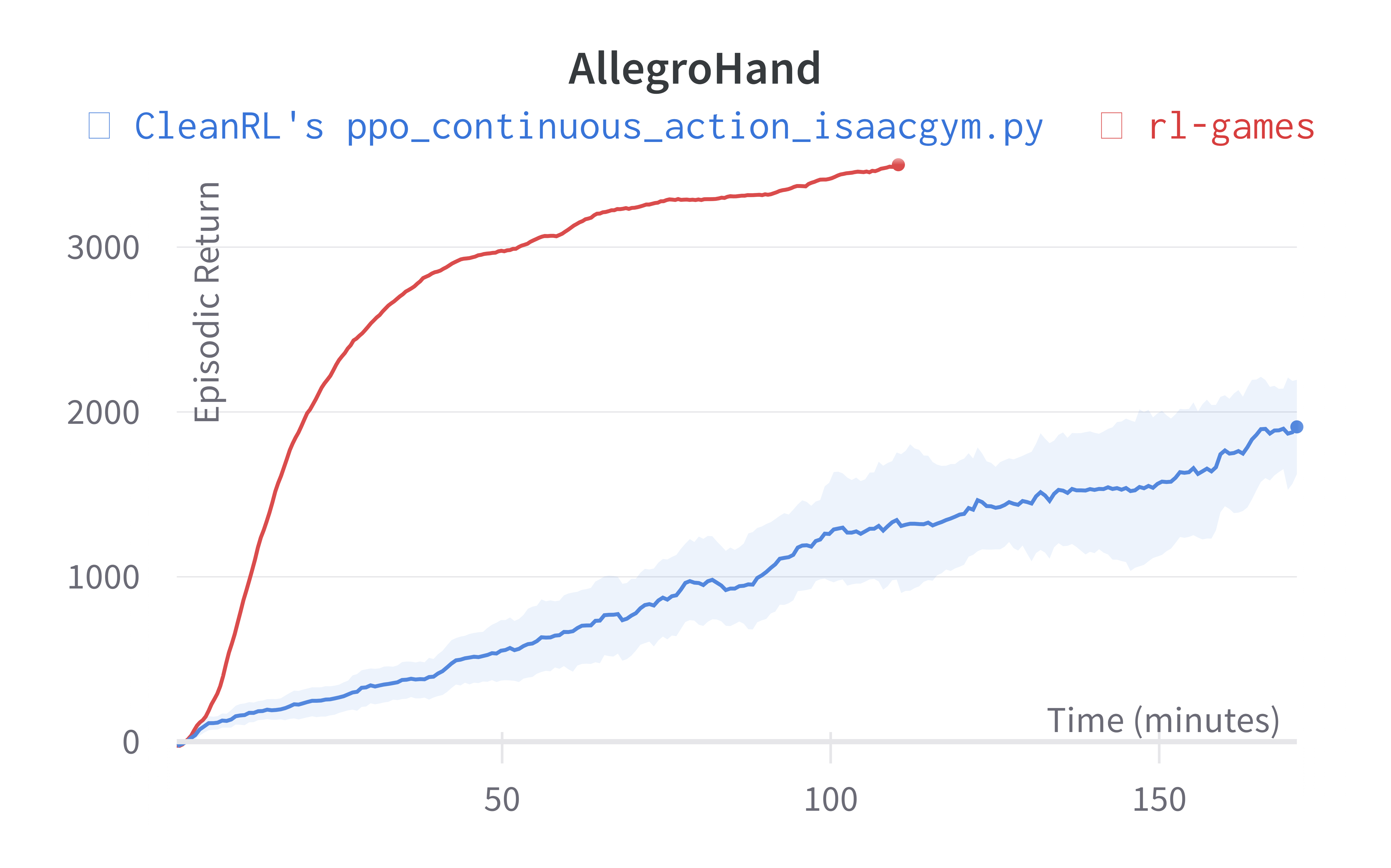
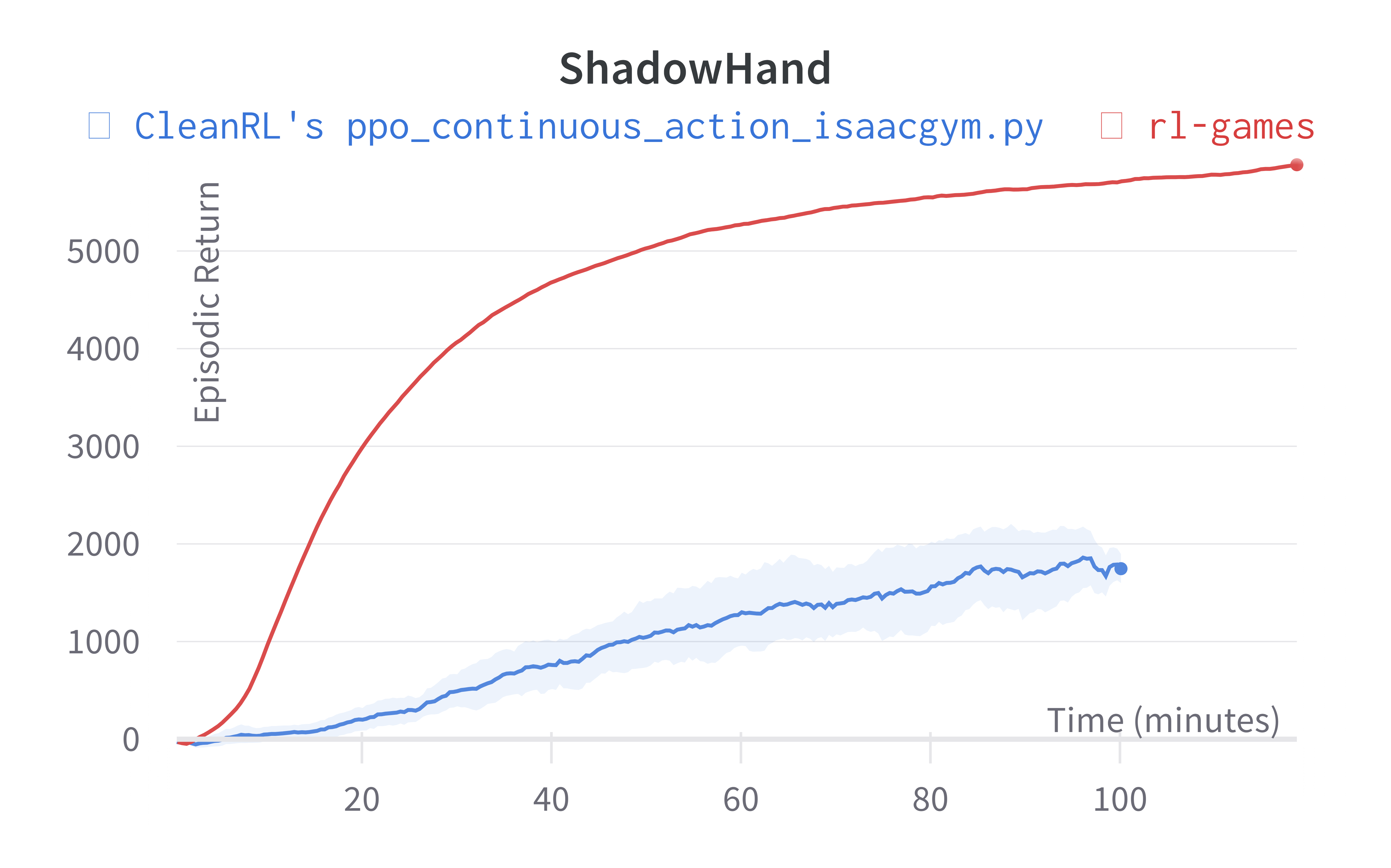
Info
Note the AllegroHand and ShadowHand experiments used the following command ppo_continuous_action_isaacgym.py --track --capture-video --num-envs 16384 --num-steps 8 --update-epochs 5 --reward-scaler 0.01 --total-timesteps 600000000 --record-video-step-frequency 3660. Costa: I was able to run this during my internship at NVIDIA, but in my home setup, the computer has less GPU memory which makes it hard to replicate the results w/ --num-envs 16384.
-
Huang, Shengyi; Dossa, Rousslan Fernand Julien; Raffin, Antonin; Kanervisto, Anssi; Wang, Weixun (2022). The 37 Implementation Details of Proximal Policy Optimization. ICLR 2022 Blog Track https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/ ↩↩↩↩
-
Andrychowicz, Marcin, Anton Raichuk, Piotr Stańczyk, Manu Orsini, Sertan Girgin, Raphael Marinier, Léonard Hussenot et al. "What matters in on-policy reinforcement learning? a large-scale empirical study." International Conference on Learning Representations 2021, https://openreview.net/forum?id=nIAxjsniDzg ↩